Projects
Generation
Audio generation leverages generative machine learning models (e.g., Variational Autoencoders, Diffusion Transformers) to create an audio waveform or a symbolic representation of audio (e.g., MIDI). Our work includes generation of music, sound effects, and speech. Highlighted projects follow. For further publications in this area, see our publications page.
-
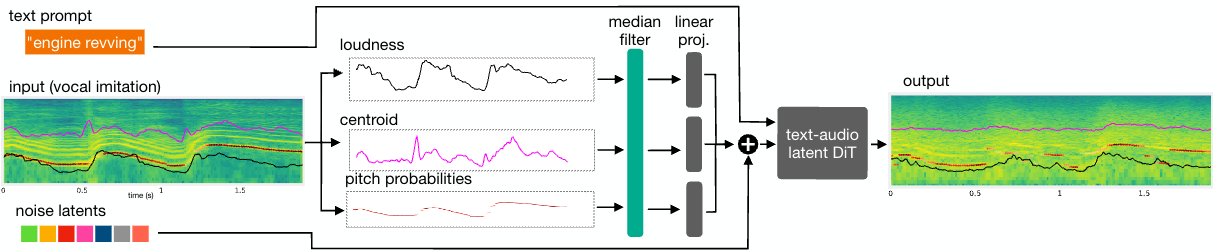
Sketch2Sound - Controllable Audio Generation via Time-Varying Signals and Sonic Imitations
In collaboration with Adobe, we present Sketch2Sound, a generative audio model capable of creating high-quality sounds from a set of interpretable time-varying control signals: loudness, brightness, and pitch, as well as text prompts. Sketch2Sound can synthesize arbitrary sounds from sonic imitations (i.e., a vocal imitation or a reference sound-shape).
-
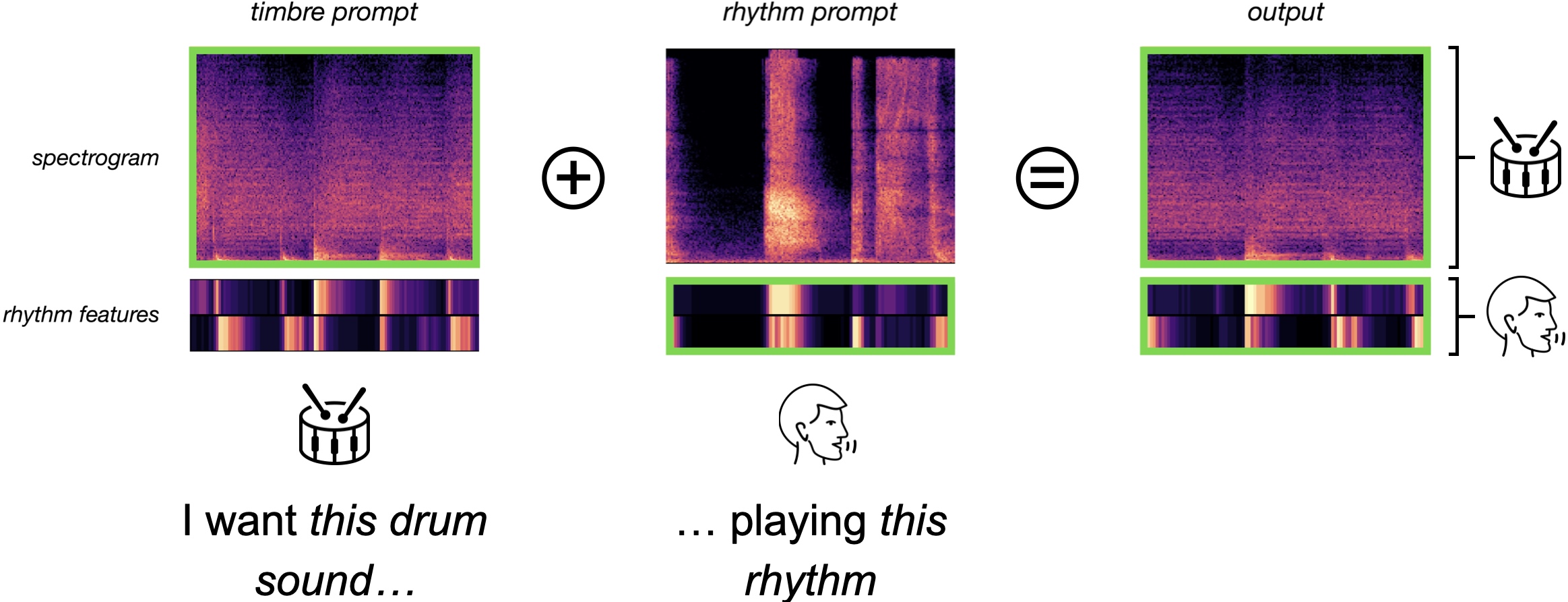
The Rhythm in Anything
we present TRIA (The Rhythm In Anything), a masked transformer model for mapping rhythmic sound gestures to high-fidelity drum recordings. Given an audio prompt of the desired rhythmic pattern and a second prompt to represent drumkit timbre, TRIA produces audio of a drumkit playing the desired rhythm (with appropriate elaborations)in the desired timbre.
-
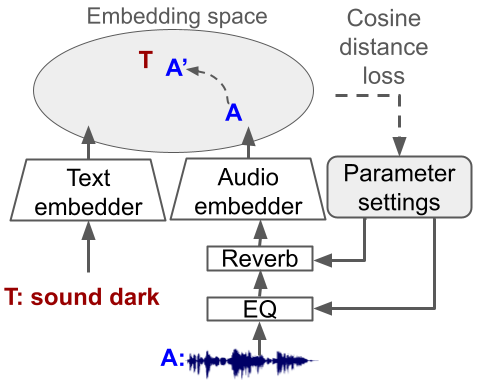
Text2FX - Harnessing CLAP Embeddings for Text-Guided Audio Effects
Text2FX leverages CLAP embeddings and differentiable digital signal processing to control audio effects, such as equalization and reverberation, using open-vocabulary natural language prompts (e.g., “make this sound in-your-face and bold”).
-

Controllable Speech Generation
Nuances in speech prosody (i.e., the pitch, timing, and loudness of speech) are a vital part of how we communicate. We develop generative machine learning models that use interpretable, disentangled representations of speech to give control over these nuances and generate speech reflecting user-specified prosody.
-
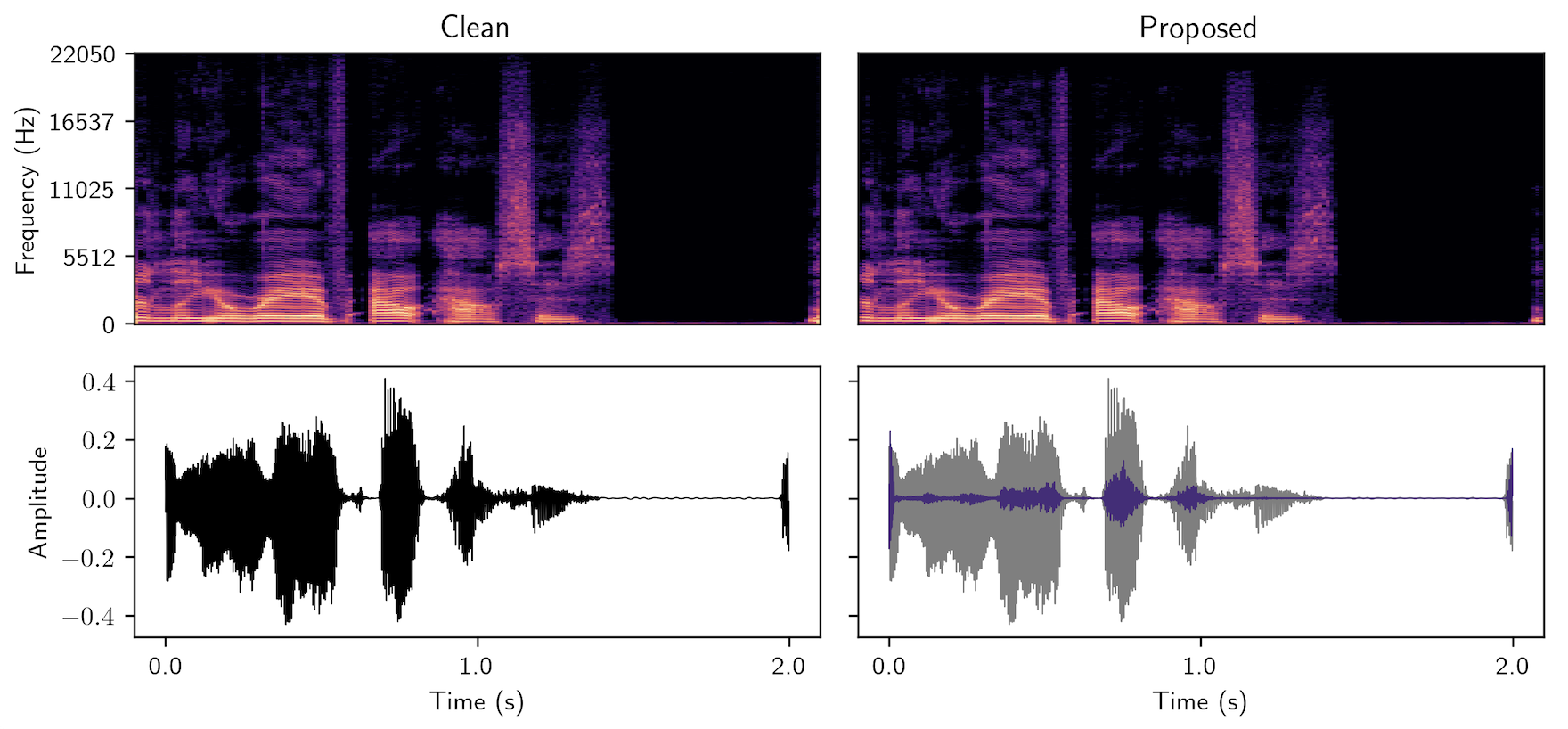
MaskMark - Robust Neural Watermarking for Real and Synthetic Speech
High-quality speech synthesis models may be used to spread misinformation or impersonate voices. Audio watermarking can combat misuse by embedding a traceable signature in generated audio. However, existing audio watermarks typically demonstrate robustness to only a small set of transformations of the watermarked audio. To address this, we propose MaskMark, a neural network-based digital audio watermarking technique optimized for speech.
-
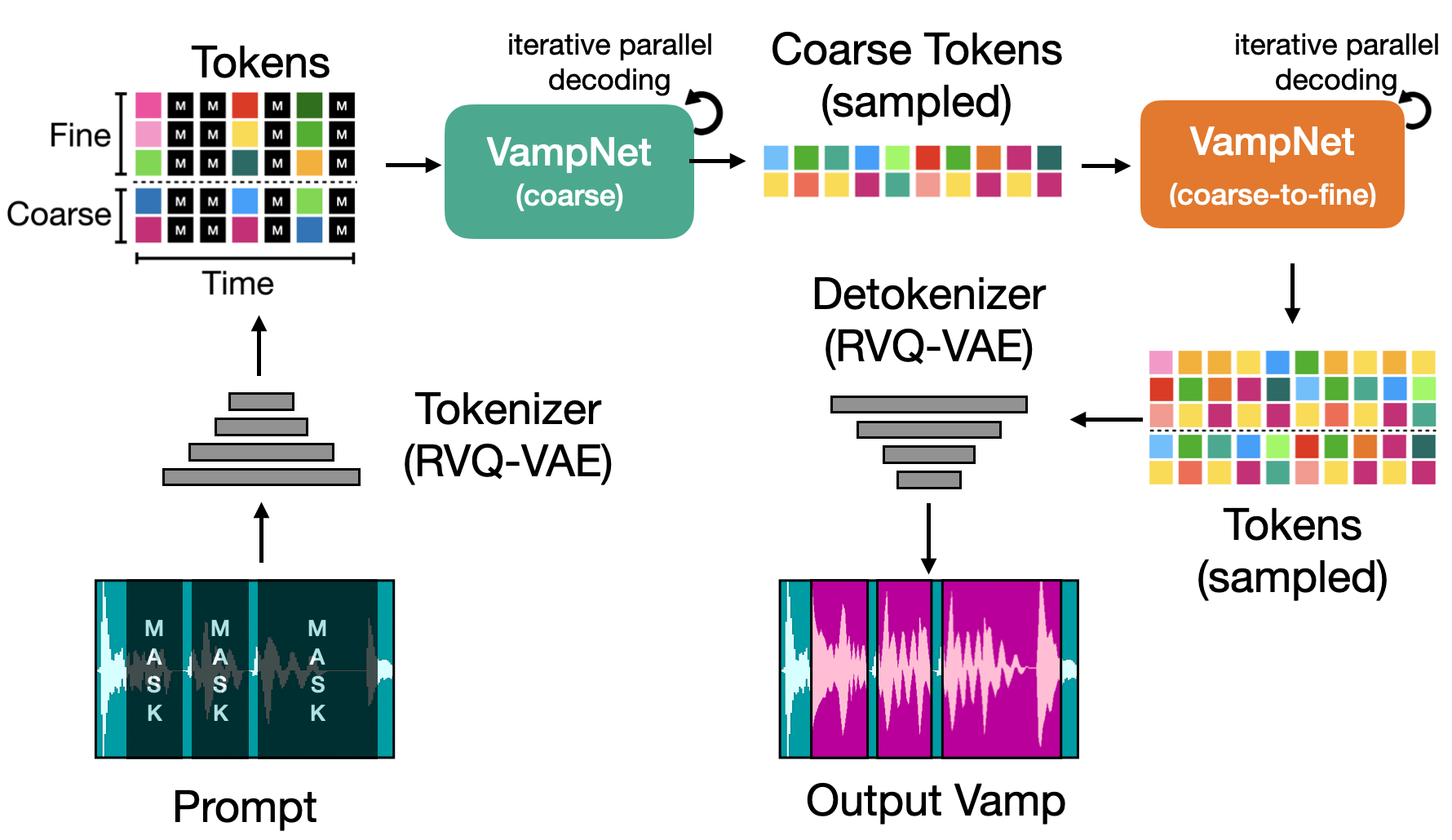
VampNet - Music Generation via Masked Acoustic Token Modeling
We introduce VampNet, a masked acoustic token modeling approach to music audio generation. VampNet lets us sample coherent music from the model by applying a variety of masking approaches (called prompts) during inference. Prompting VampNet appropriately, enables music compression, inpainting, outpainting, continuation, and looping with variation (vamping). This makes VampNet a powerful music co-creation tool.
-
Symbolic music generation
Symbolic music generation uses machine learning to produce music in a symbolic form, such as the Musical Instrument Digital Interface (MIDI) format. Generating music in a symbolic format has the advantages of being both interpretable (e.g., as pitch, duration, and loudness values) and editable in standard digital audio workstations (DAWs).
Interfaces
Improving audio production tools meaningfully enhances the creative output of musicians, podcasters, producers and videographers. We focus on bridging the gap between the intentions of creators and the interfaces of audio recording and manipulation tools they use. Our work in this area has a strong human-centered machine learning component. Representative projects in the area are below. For further publications in this area, see our publications page.
-

Deep Learning Tools for Audacity
We provide a software framework that lets deep learning practitioners easily integrate their own PyTorch models into the open-source Audacity DAW. This lets ML audio researchers put tools in the hands of sound artists without doing DAW-specific development work.
-

Eyes Free Audio Production
This project focuses on building novel accessible tools for creating audio-based content like music or podcasts. The tools should support the needs of blind creators, whether working independently or on teams with sighted collaborators.
-

HARP - Bringing Deep Learning to the DAW with Hosted, Asynchronous, Remote Processing
HARP is an ARA plug-in that allows for hosted, asynchronous, remote processing of audio with deep learning models. HARP works by routing audio from a digital audio workstation (DAW) through Gradio endpoints. Because Gradio apps can be hosted locally or in the cloud (e.g., HuggingFace Spaces), HARP lets users of Digital Audio Workstations (e.g. Reaper) access large state-of-the-art models in the cloud, without breaking their within-DAW workflow.
-
Audio production interfaces that learn from user interaction
We use metaphors and techniques familiar to musicians to produce customizable environments for music creation, with a focus on bridging the gap between the intentions of both amateur and professional musicians and the audio manipulation tools available through software.
Robustness
Neural network-based audio interfaces should be robust to various input distortions, especially in sensitive applications. We study the behavior of audio models under maliciously-crafted inputs - called adversarial examples - in order to better understand how to secure audio interfaces against bad-faith actors and naturally-occurring distortions. For further publications in this area, see our publications page.
-
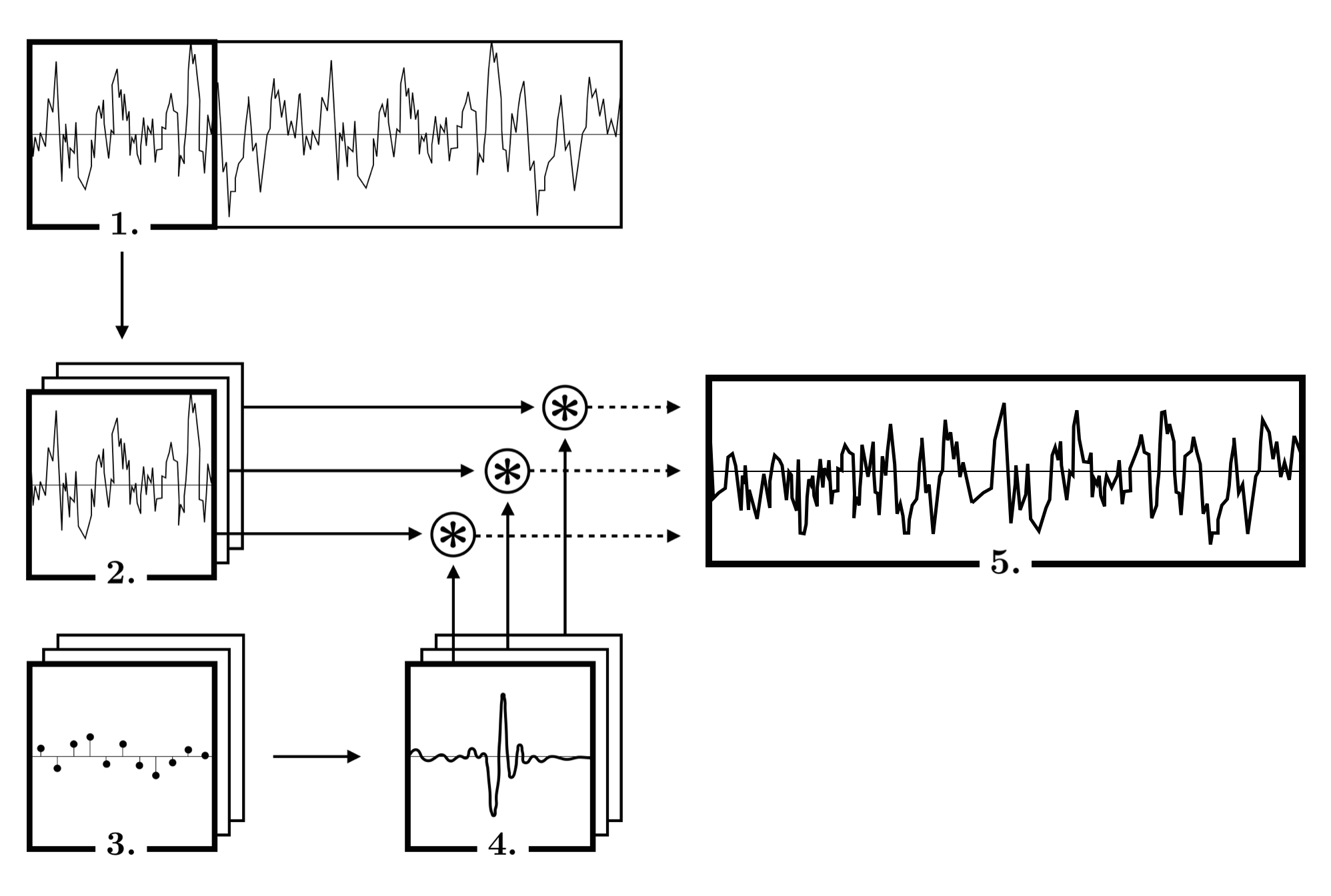
Audio adversarial examples with adaptive filtering
We demonstrate a novel audio-domain adversarial attack that modifies benign audio using an interpretable and differentiable parametric transformation - adaptive filtering. Unlike existing state-of-the-art attacks, our proposed method does not require a complex optimization procedure or generative model, relying only on a simple variant of gradient descent to tune filter parameters.
-
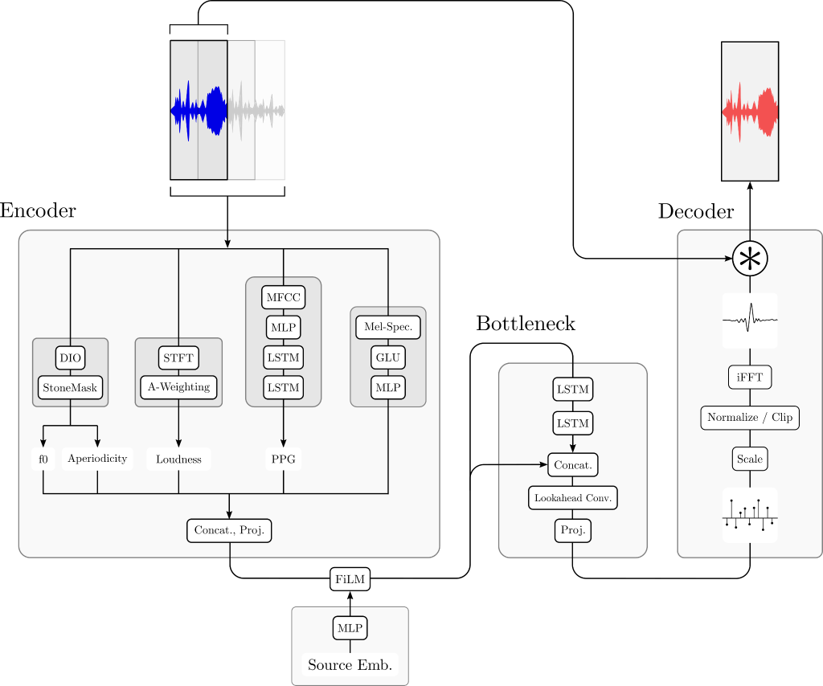
Privacy through Real-Time Adversarial Attacks with Audio-to-Audio Models
As governments and corporations adopt deep learning systems to apply voice ID at scale, concerns about security and privacy naturally emerge. We propose a neural network model capable of inperceptibly modifying a user’s voice in real-time to prevent speaker recognition from identifying their voce.
Separation
Audio source separation is the process of extracting a single sound (e.g. one violin) from a mixture of sounds (a string quartet). This is an ongoing research area in the lab. Source separation is the audio analog of scene segmentation in computer vision and is a foundational technology that improves or enables speech recogntion, sound object labeling, music transcription,hearing aids and other technologies. For further publications in this area, see our publications page.
-
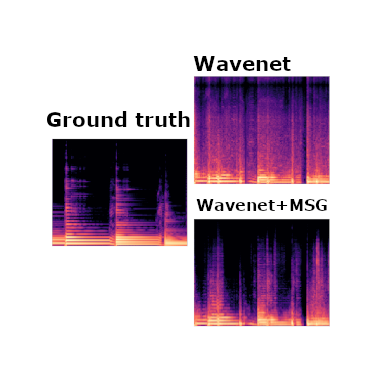
Music Separation Enhancement with Generative Modeling
We introduce Make it Sound Good (MSG), a post-processor that enhances the output quality of source separation systems like Demucs, Wavenet, Spleeter, and OpenUnmix.
-

nussl
The Northwestern University Source Separation Library (nussl) provides implementations of common audio source separation algorithms as well as an easy-to-use framework for prototyping and adding new algorithms.
-
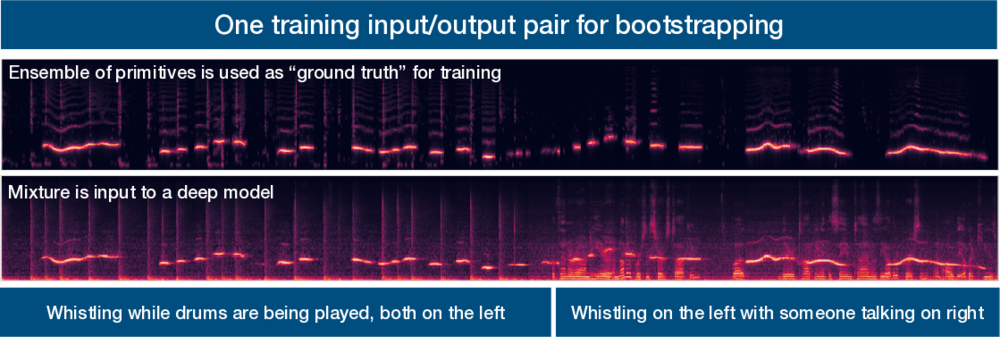
Bootstrapping deep learning models for computer audition
We are developing methods that allow a deep learning model learn to segment and label an audio scene (e.g. separate and label all the overlapped talkers at a cocktail party) without ever having been taught from isolated sound sources.
-
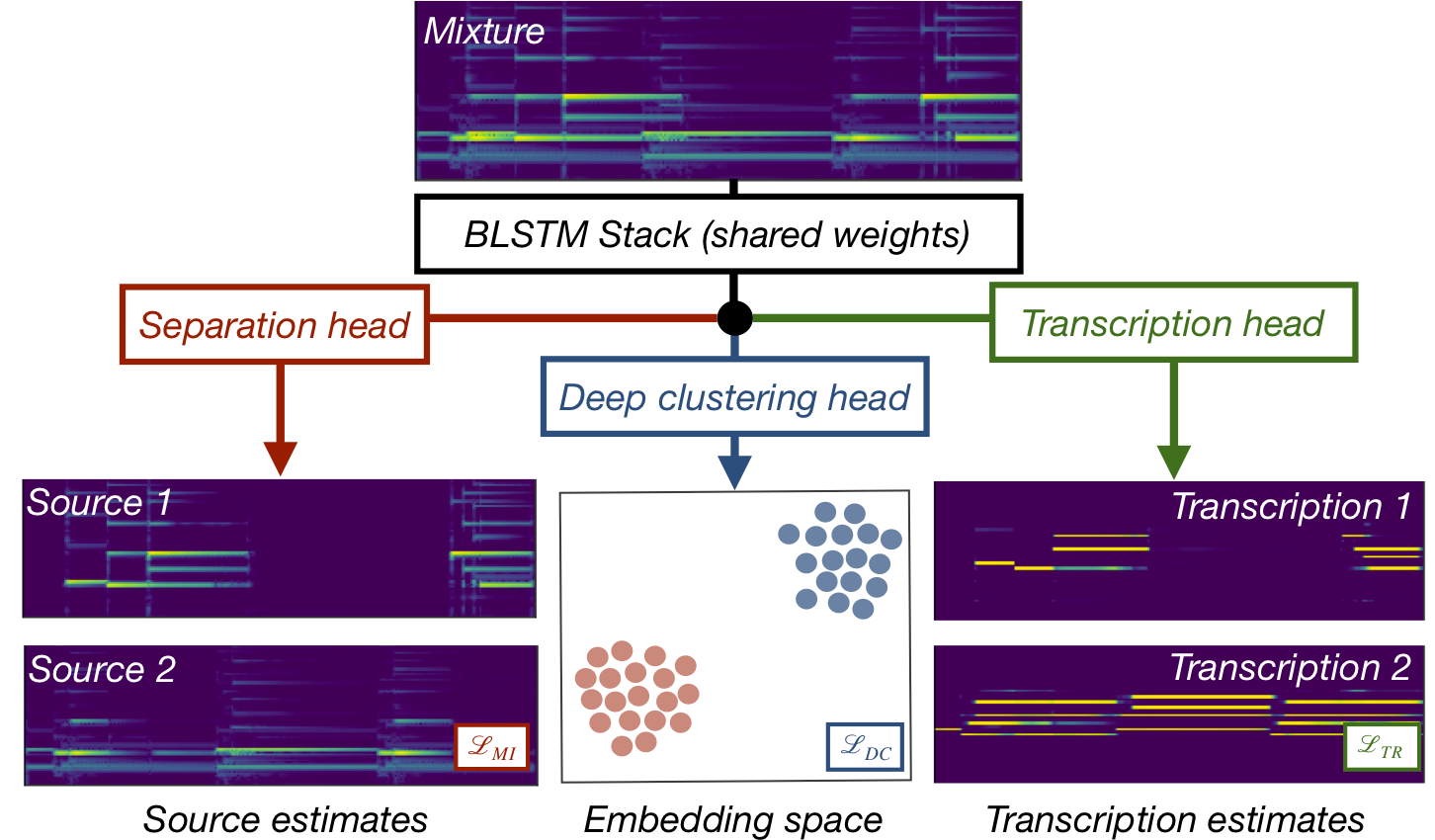
Cerberus, simultaneous audio separation and transcription
Cerberus is a single deep learning architecture that can simultaneously separate sources in a musical mixture and transcribe those sources.
-

Multi-resolution Common Fate Transform
The Multi-resolution Common Fate Transform (MCFT) is an audio signal representation developed in our lab in the context of audio source separation.
-
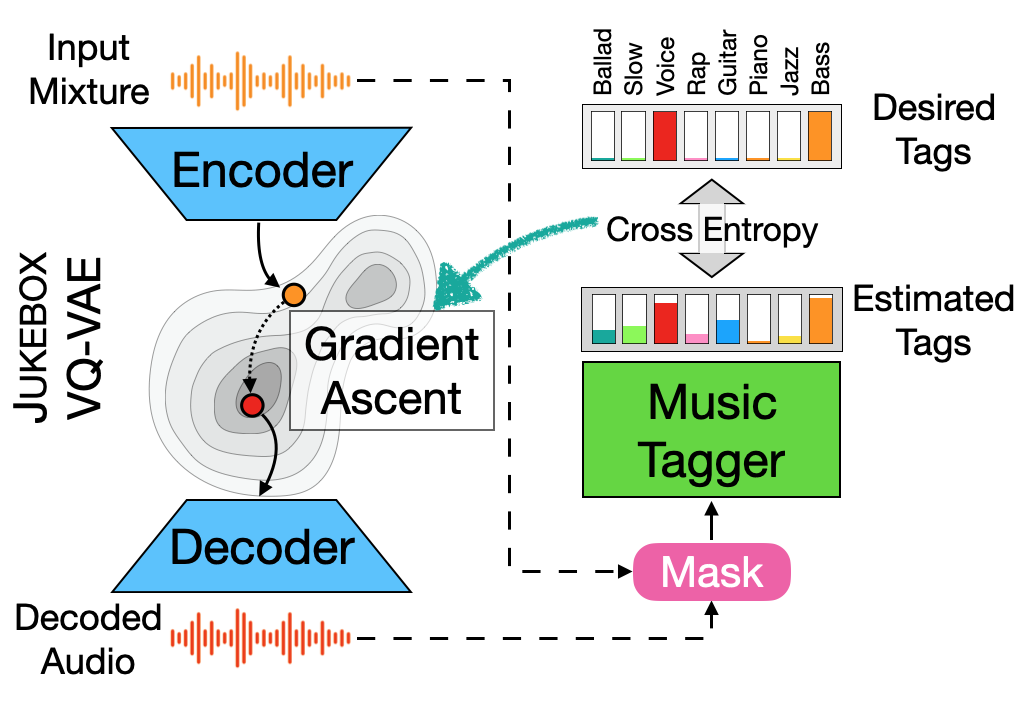
Unsupervised Source Separation By Steering Pretrained Music Models
We showcase an unsupervised method that repurposes deep models trained for music generation and music tagging for audio source separation, without any retraining.
Search
Content-addressable search through collections of many audio files (thousands) or lengthy audio files (hours) is an ongoing research area. In this work, we develop and apply cutting edge techniques in machine learning, signal processing and interface design. This is part of a collaboration with the University of Rochester AIR lab and is supported by the National Science Foundation. Representative recent projects in this area are below. For further publications in this area, see our publications page.
-
ISED
Interactive Sound Event Detector (I-SED) is a human-in-the-loop interface for sound event annotation that helps users label sound events of interest within a lengthy recording quickly. The annotation is performed by a collaboration between a user and a machine.
-
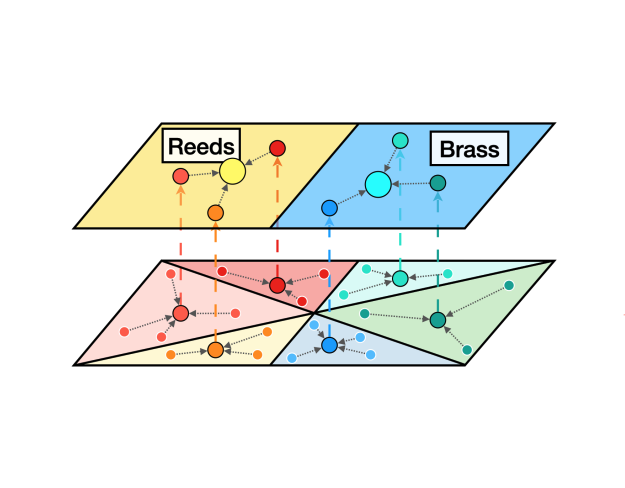
Leveraging Hierarchical Structures for Few-Shot Musical Instrument Recognition
In this work, we exploit hierarchical relationships between instruments in a few-shot learning setup to enable classification of a wider set of musical instruments, given a few examples at inference.
-
