VampNet - Music Generation via Masked Acoustic Token Modeling
Hugo Flores Garcia, Prem Seetharaman, Rithesh Kumar, Bryan Pardo
This work supported by NSF Award Number 2222369
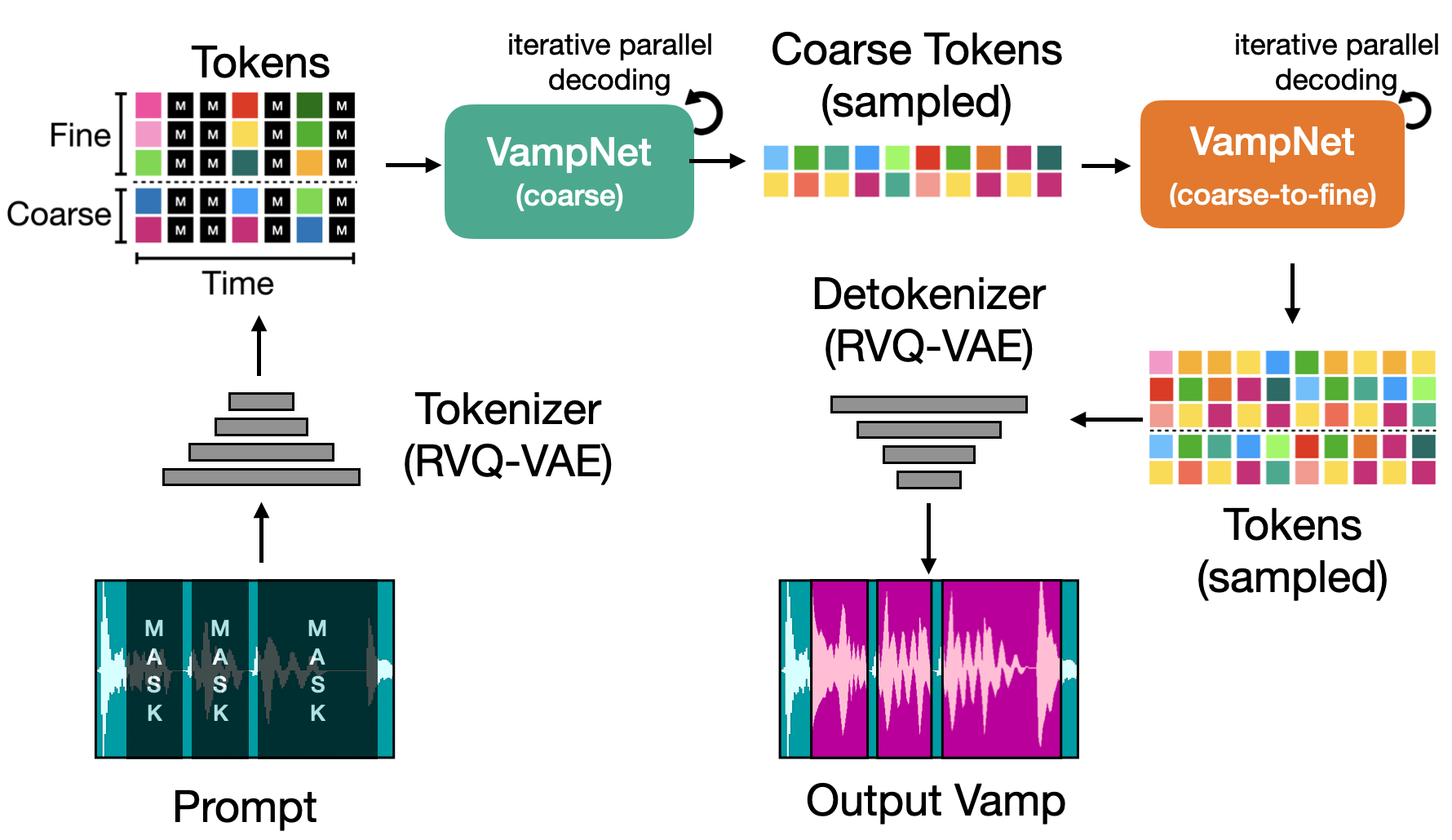
We introduce VampNet, a masked acoustic token modeling approach to music audio generation. VampNet lets us sample coherent music from the model by applying a variety of masking approaches (called prompts) during inference. Prompting VampNet appropriately, enables music compression, inpainting, outpainting, continuation, and looping with variation (vamping). This makes VampNet a powerful music co-creation tool.
VampNet is non-autoregressive, leveraging a bidirectional transformer architecture that attends to all tokens in a forward pass. With just 36 sampling passes (compared to hundreds in the autoregressive approach), VampNet generates coherent high-fidelity musical waveforms. For more, try the demo listen to our audio examples, read the paper, peruse the sourcecode, or just watch the video.
Demo Audio Sourcecode
Related publications
[pdf] H. Flores, P. P. Seetharaman, R. Kumar, and B. Pardo, “VampNet: Music Generation via Masked Acoustic Token Modeling,” International Society of the Society of Music Information Retrieval (ISMIR), 2023.