Audio adversarial examples with adaptive filtering
Patrick O'Reilly, Pranjal Awasthi, Aravindan Vijayaraghavan, Bryan Pardo
Audio Examples
We demonstrate a novel audio-domain adversarial attack that modifies benign audio using an interpretable and differentiable parametric transformation - adaptive filtering. Unlike existing state-of-the-art attacks, our proposed method does not require a complex optimization procedure or generative model, relying only on a simple variant of gradient descent to tune filter parameters.
Background: Audio Interfaces are Vulnerable to Adversarial Examples
Deep neural networks achieve state-of-the-art performance on many audio tasks, including speaker verification, and as a result have been incorporated into voice-based systems for authentication and control in a wide variety of products. While deep networks are powerful classifiers, they are known to be vulnerable to adversarial examples, artificially-generated perturbations of natural instances that cause a network to make incorrect predictions. This vulnerability presents an opportunity for malicious actors to gain access to and influence the behavior of various products by surreptitiously passing adversarially-crafted audio to the underlying neural network systems. The research community has developed a number of audio-domain adversarial attacks to evaluate the robustness of deep neural networks across a variety of tasks, and we continue this work here.
Attacking with Adaptive Filtering
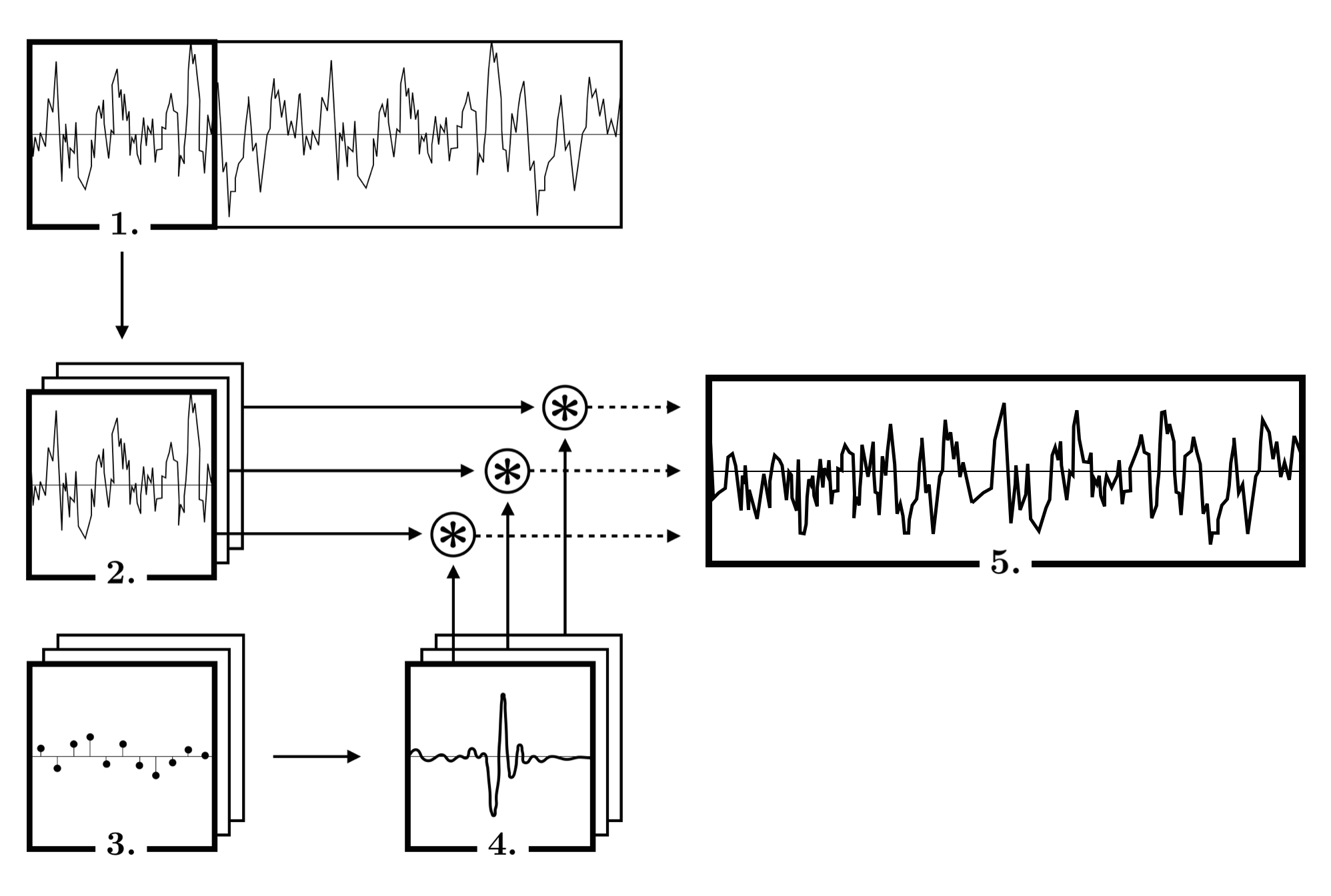
Rather than optimize an additive waveform perturbation of a benign recording, as is typical, we optimize the parameters of an adaptive filter in the form of a time-varying frequency-domain transfer function. We then apply our filter to benign audio frame-by-frame to produce adversarial examples.
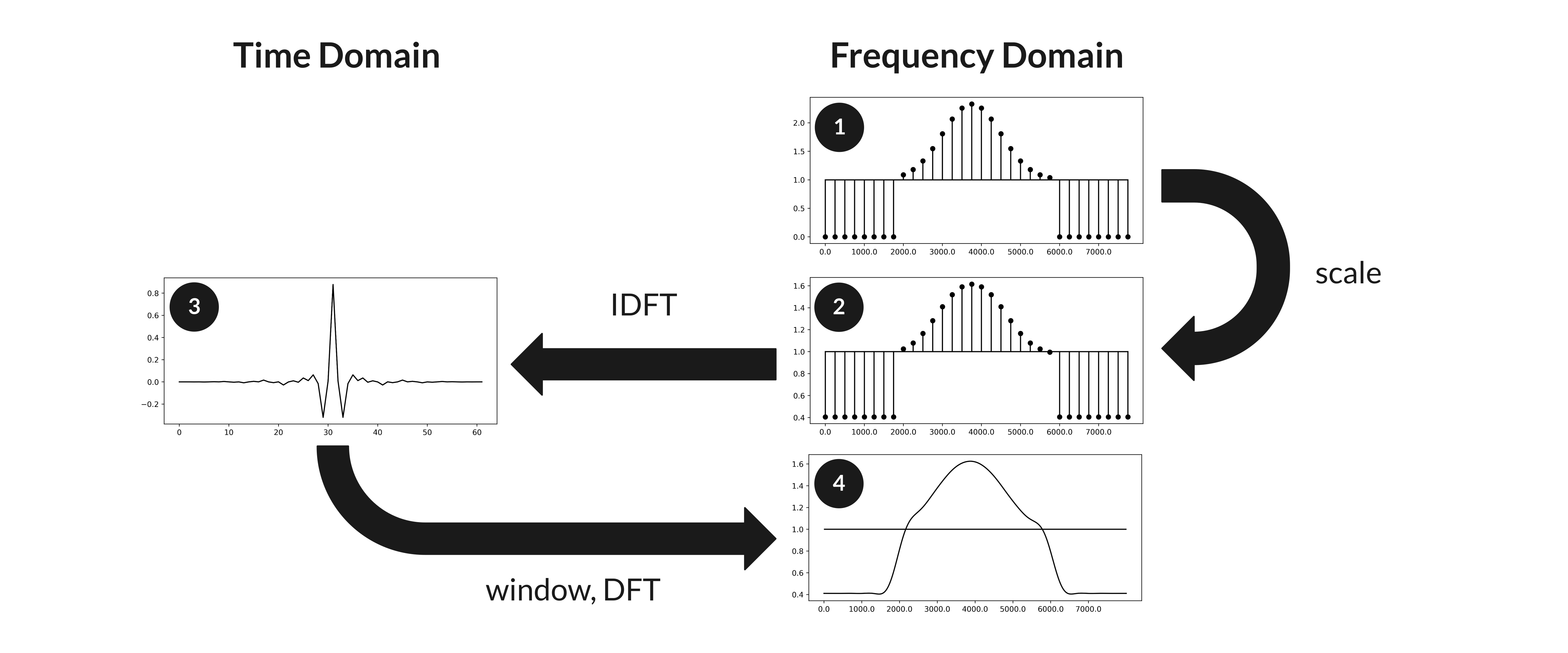
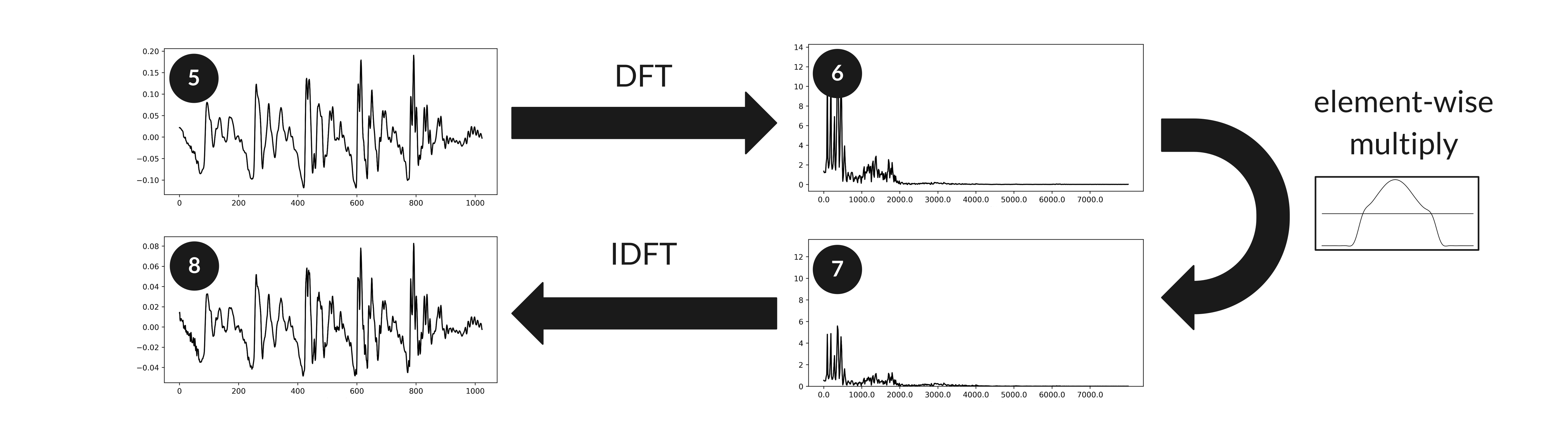
Above, for each audio frame we adversarially parameterize a sparsely-sampled frequency-domain transfer function (1). After scaling (2), we convert each transfer function to a time-domain impulse response via the IDFT and apply a Hann window (3). We then take the DFT to obtain a smoothed, interpolated transfer function (4) which can be applied to a frame of audio input (5) via element-wise multiplication in the Fourier domain (6, 7). Finally, we combine the filtered frames in the time domain via overlap-add (8) to obtain our adversarially-filtered audio.
Attacking in Realistic Settings
In order to craft attacks that work well in real-world playback scenarios (“over-the-air”), we can optimize through simulated distortions that mimic the properties of acoustic environments (e.g. reverb, noise, time-domain offset).
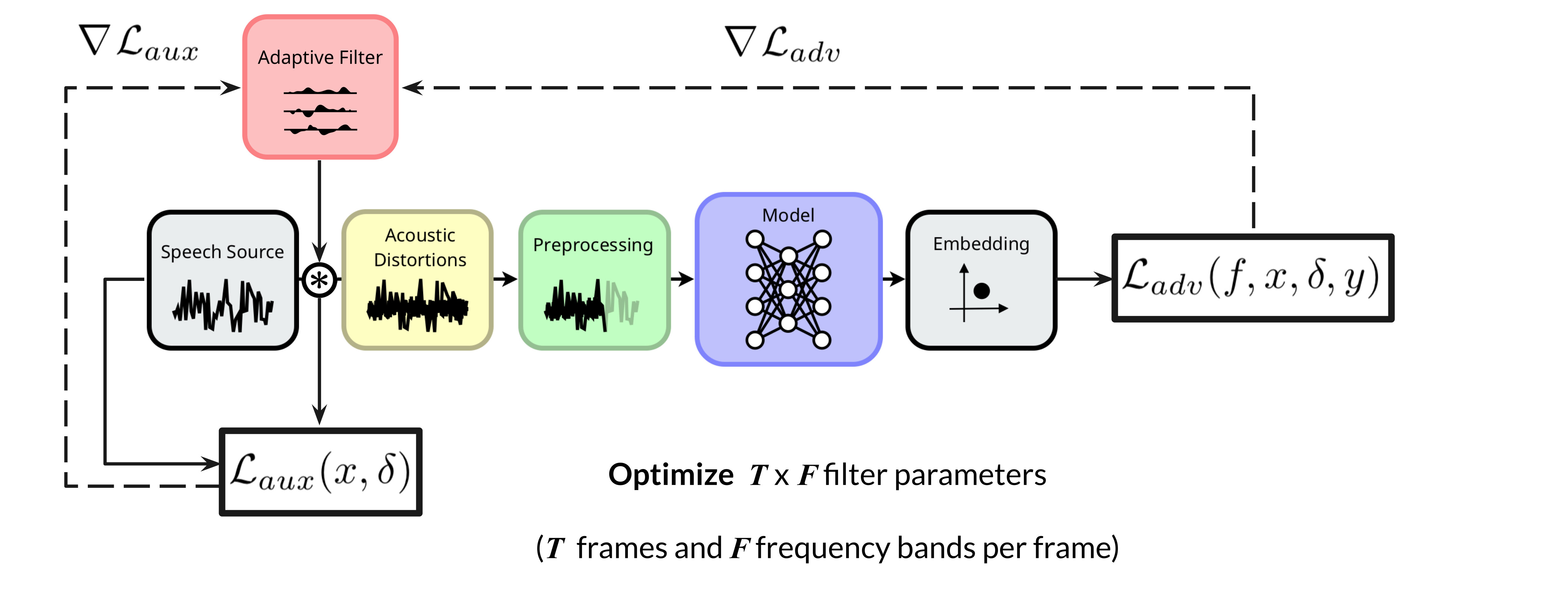
Over-the-air attacks often require large-magnitude perturbations of the original audio in order to survive playback, and for typical waveform-additive attacks, this means noisy artifacts. We demonstrate the effectiveness of our filtering method by performing over-the-air attacks against a state-of-the-art speaker verification model, and show that our attack can match or exceed the perceptual quality of existing attacks when controlling for effectiveness. In a user study, listeners rate our attack as less conspicuous than a state-of-the-art additive frequency-masking attack by a ratio of 2-to-1. Our results demonstrate the potential of transformations beyond direct waveform addition for concealing high-magnitude adversarial perturbations, allowing adversaries to attack more effectively in challenging real-world settings.
Examples: Existing Methods Introduce Noise
Below, we provide examples of over-the-air attacks on a speaker verification system. In this scenario, attacks modify a recording of the source speaker to trick the system into recognizing the target speaker. The baseline attack relies on a state-of-the-art frequency-masking loss and multi-stage optimization procedure, while our attack sidesteps these requirements using adaptive filtering. Because both methods are relatively inconspicuous, we recommend listening to these examples using headphones.
Because our proposed filter attack is multiplicative rather than additive, it does not introduce noise into silent regions of the waveform. In this example, listen to the end of each recording – the baseline attack adds noise, while the proposed attack remains silent.
| Source Speaker | Target Speaker | Baseline Attack | Our Attack |
|---|---|---|---|
This noise is often audible throughout attacks generated with the baseline method, not just in silent regions:
| Source Speaker | Target Speaker | Baseline Attack | Our Attack |
|---|---|---|---|
Audio for all attacks included in our over-the-air evaluation and perceptual study can be found here.