Privacy through Real-Time Adversarial Attacks with Audio-to-Audio Models
Patrick O'Reilly, Andreas Bugler, Keshav Bhandari, Max Morrison, Bryan Pardo
Audio Examples & Code
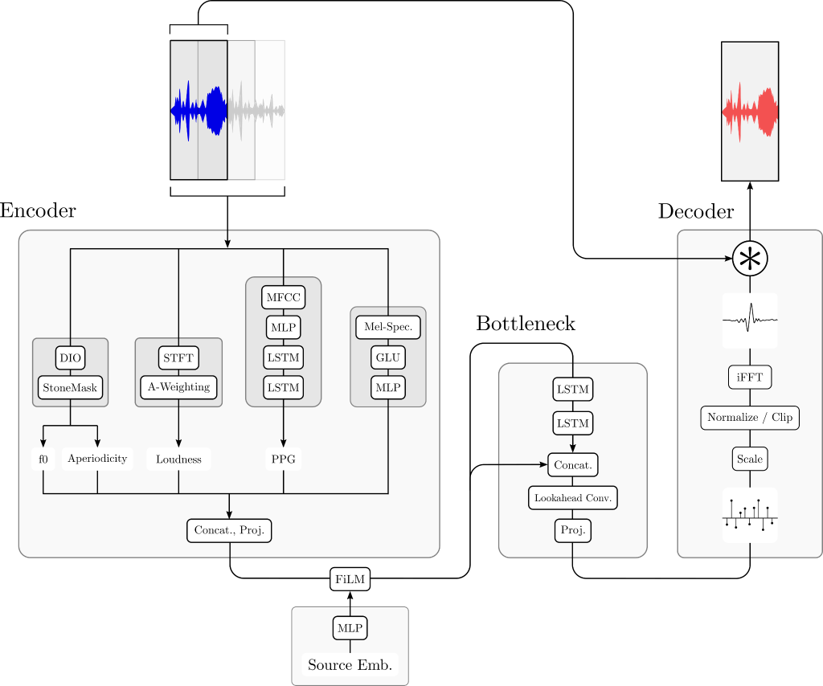
As governments and corporations adopt deep learning systems to apply voice ID at scale, concerns about security and privacy naturally emerge. We propose a neural network model capable of inperceptibly modifying a user’s voice in real-time to prevent speaker recognition from identifying their voce.
Related publications
[pdf] P. O’Reilly, A. Bugler, K. Bhandari, M. Morrison, and B. Pardo, “VoiceBlock: Privacy through Real-Time Adversarial Attacks with Audio-to-Audio Models,” in Neural Information Processing Systems, 2022.