Bootstrapping deep learning models for computer audition
Prem Seetharaman and Bryan Pardo
Audio examples
We are developing methods that allow a deep learning model learn to segment and label an audio scene (e.g. separate and label all the overlapped talkers at a cocktail party) without ever having been taught from isolated sound sources.
Computer audition is the study of how machines can organize, parse, and understand the auditory ``lake’’ of activity around us. A fundamental problem in computer audition is audio source separation. Source separation is the isolation of a specific sound (e.g. a single speaker) in a complex audio scene, like a cocktail party. Humans, as evidenced by our daily experience with sounds as well as empirical studies manage the source separation task very effectively, attending to sources of interest in complex scenes. We create computational methods for audio source separation that are inspired by the abilities of humans.
Deep learning approaches are currently state-of-the-art for source separation tasks. They are typically trained on many examples (e.g. tens of thousands) where each source (e.g. a voice) was recorded in isolation and then the recordings are artificially mixed together. The mixture and the ground truth decomposition of the mixture are presented to the learner as the desired input/output examples. Although we have large collections of isolated speech, we don’t have large collections of isolated recordings for every arbitrary sound. This fundamentally limits the range of mixtures and sounds that existing models can learn to separate.
In contrast, humans are never given a decomposition of the complex auditory scenes they encounter, yet they develop broadly robust abilities to parse audio scenes. There is experimental evidence that the brain uses fundamental grouping mechanisms, called primitives, to segment audio scenes even when they are composed of never-before-heard sounds. This, in turn allows learning about sound sources without the requirement to hear them in isolation.
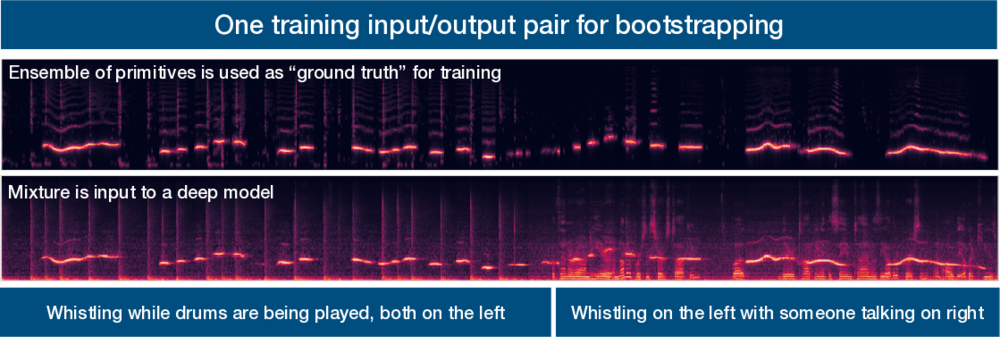
The problems we are concerned with are the following: How can we learn audio source separation models directly from complex auditory scenes instead of from artificial scenes created to give us perfect ground truth? How can we leverage a combination of learned and primitive source separation models to produce robust source separation that performs well even when mixing conditions vary?
Our approach for training a deep computer audition model without ground truth is as follows. We first apply primitive audio source separation algorithms to an auditory scene. These algorithms are inspired by human audition, such as our tendencies to group sources by spatial location, repeating vs not repeating, common fate, pitch and time proximity, and so on. Then, we estimate the confidence in the labels produced by the primitives. The goal is to focus the learning process for the deep network on time-frequency points whose labels are more likely to be correct. Finally, we train a network using the labels produced by the primitive audio source separation algorithms in conjunction with a modified deep clustering loss function that incorporates the concept of confidence weights. This training methodology makes the network focus on points that we are more confident in. The trained network can then be applied in situations where primitives fail. The result is a source separation model that can learn to segment the auditory scene without ground truth by bootstrapping its understanding of the auditory world using primitive unsupervised audio source separation algorithms.