Cerberus, simultaneous audio separation and transcription
Ethan Manilow, Prem Seetharaman, Bryan Pardo
Audio examples
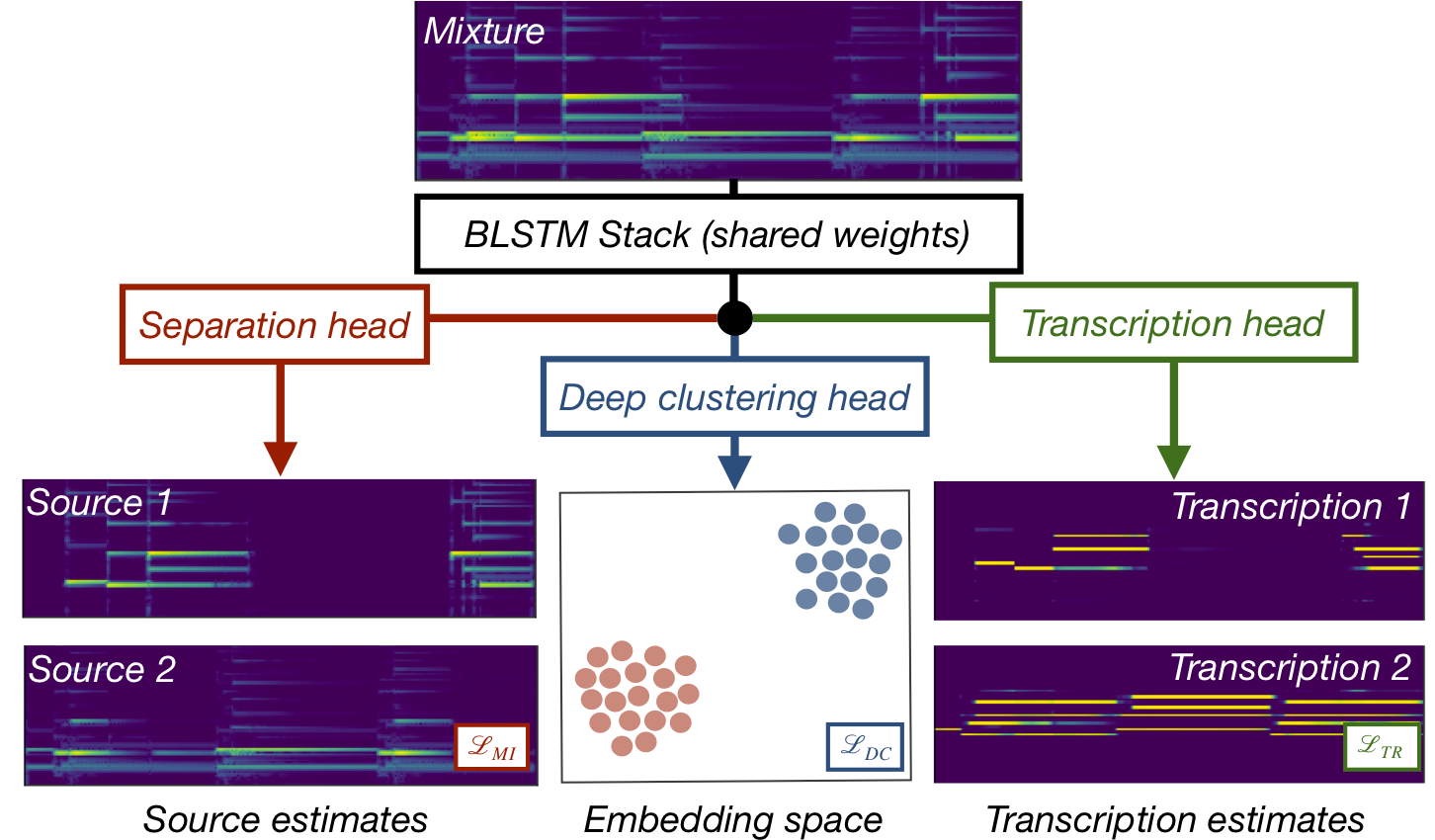
Cerberus is a single deep learning architecture that can simultaneously separate sources in a musical mixture and transcribe those sources.
We present a single deep learning architecture that can both separate an audio recording of a musical mixture into constituent single-instrument recordings and transcribe these instruments into a human-readable format at the same time, learning a shared musical representation for both tasks. This novel architecture, which we call Cerberus, builds on the Chimera network for source separation by adding a third “head” for transcription. By training each head with different losses, we are able to jointly learn how to separate and transcribe up to 5 instruments in our experiments with a single network. We show that the two tasks are highly complementary with one another and when learned jointly, lead to Cerberus networks that are better at both separation and transcription and generalize better to unseen mixtures.