Unsupervised Source Separation By Steering Pretrained Music Models
Ethan Manilow, Patrick O'Reilly, Prem Seetharaman, Bryan Pardo
Audio examples
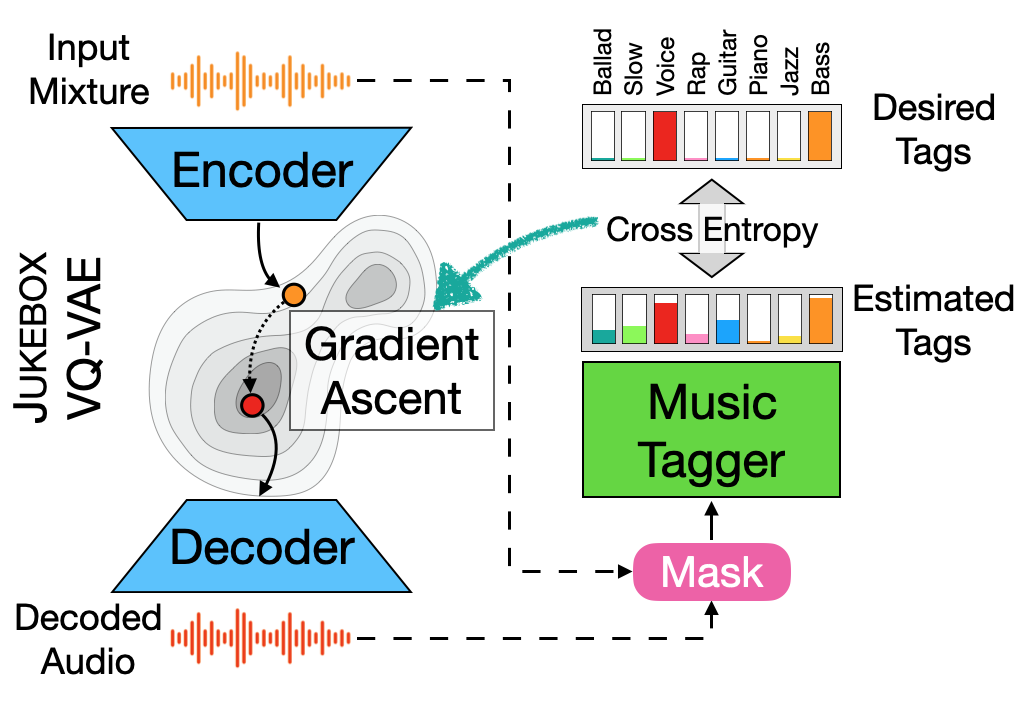
We showcase an unsupervised method that repurposes deep models trained for music generation and music tagging for audio source separation, without any retraining. An audio generation model is conditioned on an input mixture, producing a latent encoding of the audio used to generate audio. This generated audio is fed to a pretrained music tagger that creates source labels. The cross-entropy loss between the tag distribution for the generated audio and a predefined distribution for an isolated source is used to guide gradient ascent in the (unchanging) latent space of the generative model. This system does not update the weights of the generative model or the tagger, and only relies on moving through the generative model’s latent space to produce separated sources. We use OpenAI’s Jukebox as the pretrained generative model, and we couple it with four kinds of pretrained music taggers (two architectures and two tagging datasets). Experimental results on two source separation datasets, show this approach can produce separation estimates for a wider variety of sources than any tested supervised or unsupervised system. This work points to the vast and heretofore untapped potential of large pretrained music models for audio-to-audio tasks like source separation.