Headed by Prof. Bryan Pardo, the Interactive Audio Lab is in the Computer Science Department of Northwestern University. We develop new methods in Generative Modeling, Signal Processing and Human Computer Interaction to make new tools for understanding, creating, and manipulating sound.
Ongoing research in the lab is applied to generation of music and speech, audio scene labeling, audio source separation, inclusive interfaces, new audio production tools and machine audition models that learn without supervision. For more see our projects page.
Latest News
New NeurIPS paper on generating whale vocalizations
Oct 23, 2025
Our tech inside Adobe's new AI-powered audio generation
Sep 1, 2025
New papers at ASSETS and ISMIR
Sep 1, 2025
Hugo Flores Garcia defends dissertation
Jul 8, 2025
Come to our NIME Workshop: Gesture & GenAI
Jun 1, 2025
New videos on our YouTube channel
May 4, 2025
$200K grant from Toyota
May 2, 2025
New paper at ICLR Workshop on GenAI Watermarking
Apr 27, 2025
Three papers accepted to ICASSP
Apr 6, 2025
Watch Bryan Pardo's recent AES talk
Oct 22, 2024
New papers at Interspeech and ISMIR
Sep 1, 2024
Max Morrison defends dissertation
Jun 1, 2024
TorchCrepe pitch tracker: 2,000,0000+ downloads.
Oct 18, 2023
Try the VampNet demo: Music Generation via Masked Acoustic Token Modeling.
Jul 1, 2023
Our tech inside Adobe's new AI-powered audio editor
Jun 1, 2023
$440K grant from NSF: Engaging Blind and Visually Impaired Youth in Computer Science through Music Programming
Jun 1, 2023
Lexie B2 hearing aids use our tech
Dec 1, 2022
$100K grant from Sony to fund speech generation
Oct 1, 2022
$1.8 million Future of Work award from NSF
Sep 12, 2022
Projects
-
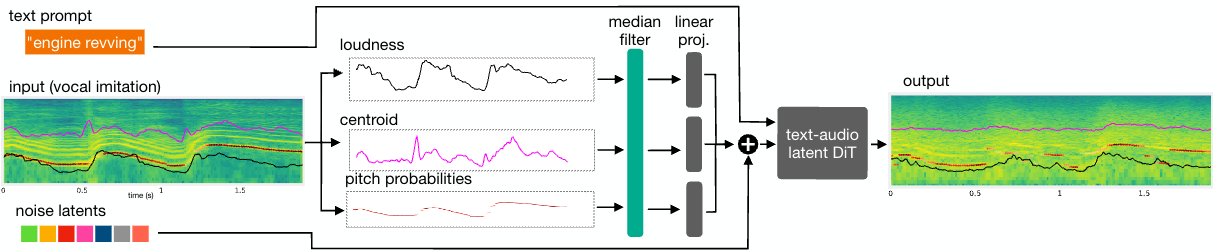
Sketch2Sound - Controllable Audio Generation via Time-Varying Signals and Sonic Imitations
Hugo Flores Garcia, Oriol Nieto, Justin Salamon, Bryan Pardo, Prem Seetharaman
In collaboration with Adobe, we present Sketch2Sound, a generative audio model capable of creating high-quality sounds from a set of interpretable time-varying control signals: loudness, brightness, and pitch, as well as text prompts. Sketch2Sound can synthesize arbitrary sounds from sonic imitations (i.e., a vocal imitation or a reference sound-shape).
-
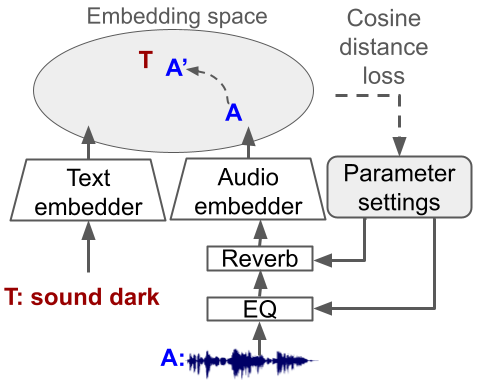
Text2FX - Harnessing CLAP Embeddings for Text-Guided Audio Effects
Annie Chu, Patrick O'Reilly, Julia Barnett, Bryan Pardo
Text2FX leverages CLAP embeddings and differentiable digital signal processing to control audio effects, such as equalization and reverberation, using open-vocabulary natural language prompts (e.g., “make this sound in-your-face and bold”).
-
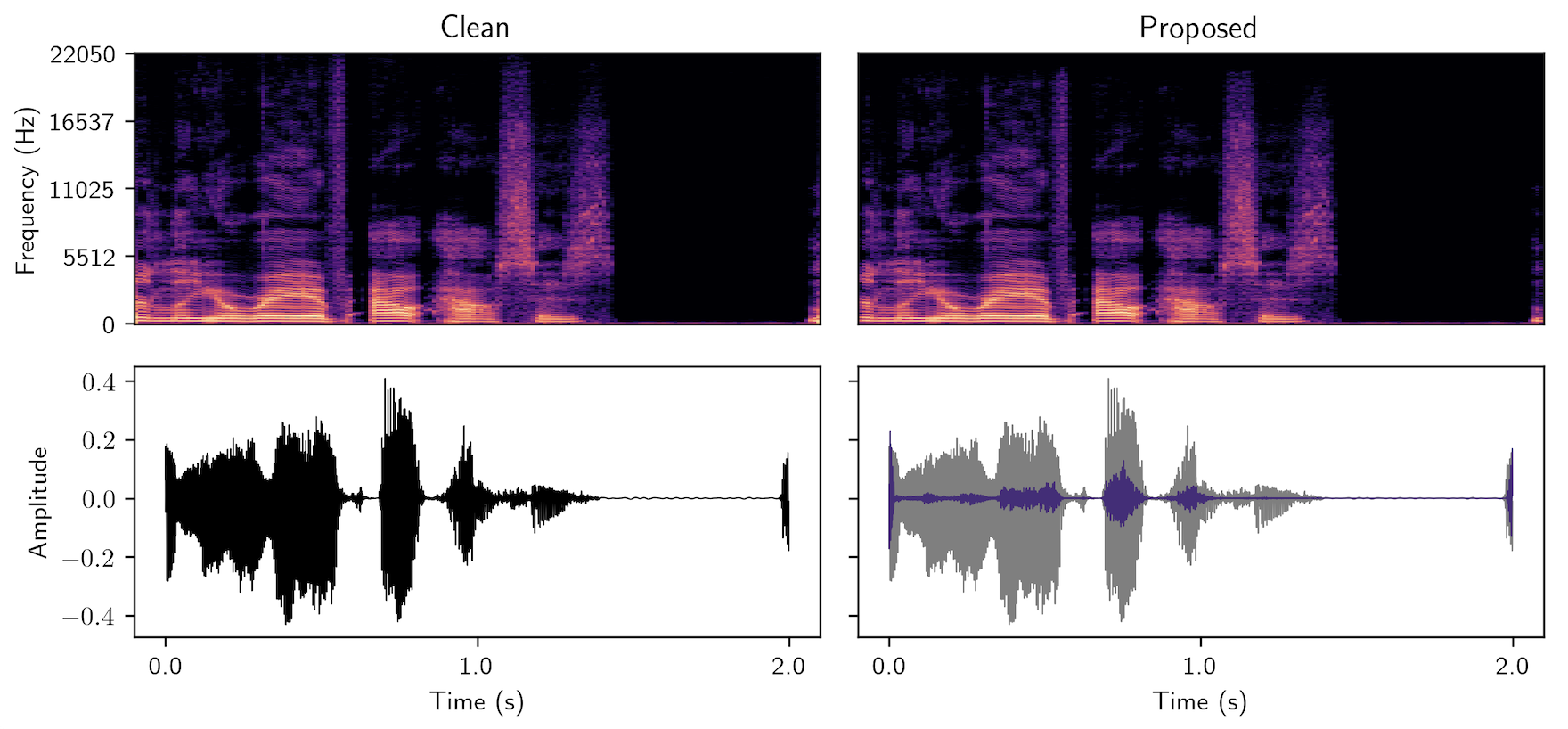
MaskMark - Robust Neural Watermarking for Real and Synthetic Speech
Patrick O'Reilly, Zeyu Jin, Jiaqi Su, Bryan Pardo
High-quality speech synthesis models may be used to spread misinformation or impersonate voices. Audio watermarking can combat misuse by embedding a traceable signature in generated audio. However, existing audio watermarks typically demonstrate robustness to only a small set of transformations of the watermarked audio. To address this, we propose MaskMark, a neural network-based digital audio watermarking technique optimized for speech.