Sketch2Sound - Controllable Audio Generation via Time-Varying Signals and Sonic Imitations
Hugo Flores Garcia, Oriol Nieto, Justin Salamon, Bryan Pardo, Prem Seetharaman
This work supported by NSF Award Number 2222369
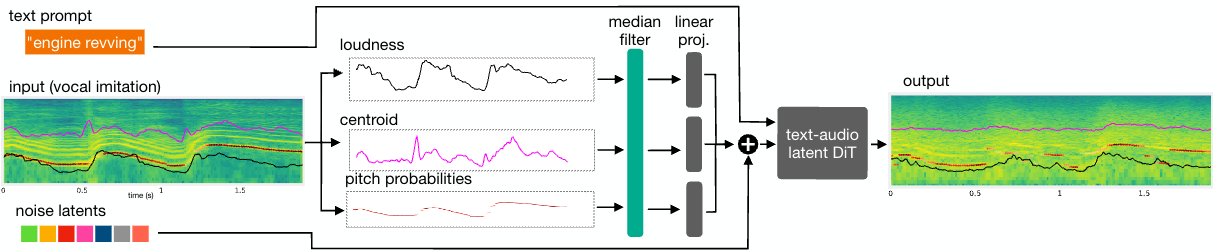
In collaboration with Adobe, we present Sketch2Sound, a generative audio model capable of creating high-quality sounds from a set of interpretable time-varying control signals: loudness, brightness, and pitch, as well as text prompts. Sketch2Sound can synthesize arbitrary sounds from sonic imitations (i.e., a vocal imitation or a reference sound-shape).
Sketch2Sound can be implemented on top of any text-to-audio latent diffusion transformer (DiT), and requires only 40k steps of fine-tuning and a single linear layer per control, making it more lightweight than existing methods like ControlNet.
September 1, 2025 NEWS: Sketch2Sound has been incorporated into Adobe’s Firefly as the Generate Sound Effects beta. Try it here!
Related publications
[pdf] H. Flores Garcia, O. Nieto, J. Salamon, B. Pardo, and P. Seetharaman, “Sketch2Sound: Controllable Audio Generation via Time-Varying Signals and Sonic Imitations,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025.