Datasets
-
Fine-grained Vocal Imitation Set
Bongjun Kim, Bryan Pardo
This dataset includes 763 crowd-sourced vocal imitations of 108 sound events. The sound event recordings were taken from a subset of Vocal Imitation Set.
-

OtoMobile
Max Morrison and Bryan Pardo
OtoMobile dataset is a collection of recordings of failing car components, created by the Interactive Audio Lab at Northwestern University.
-
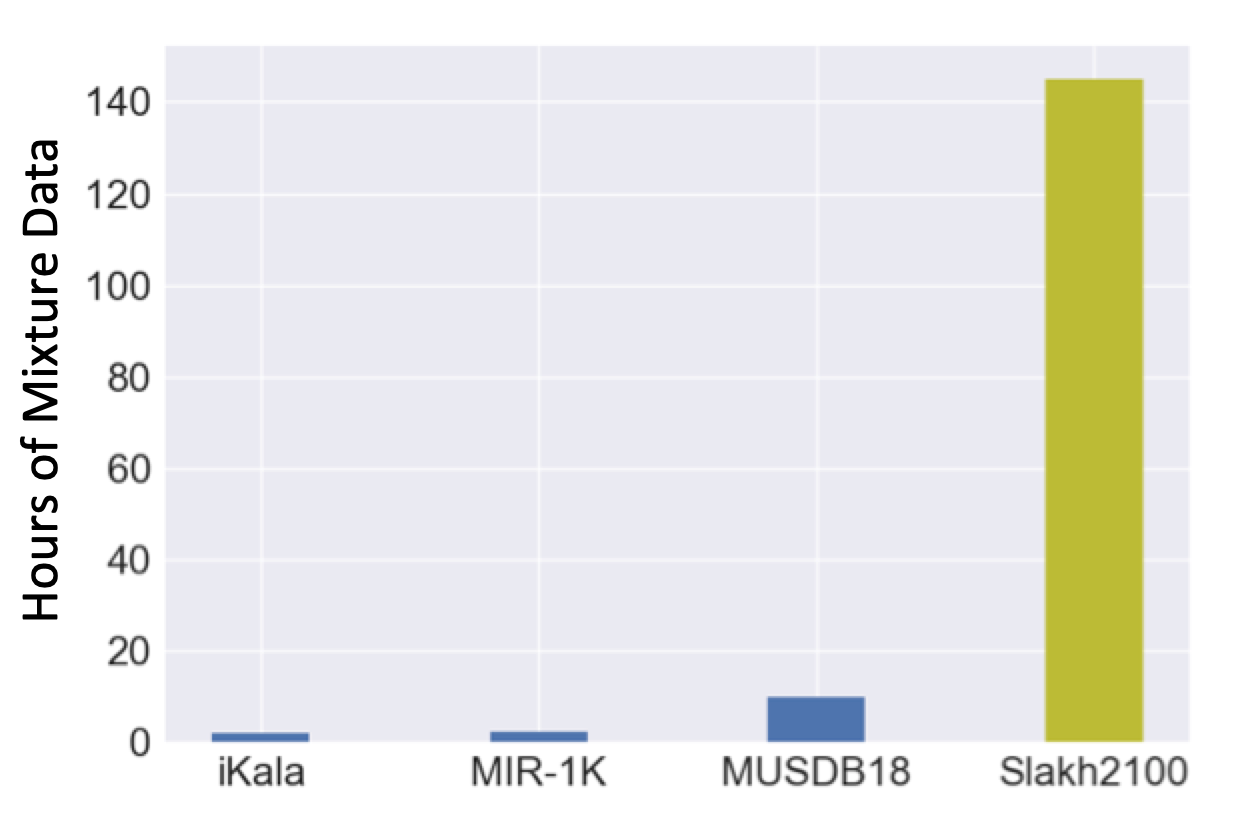
Slakh
Ethan Manilow, Gordon Wichern, Prem Seetharaman, Jonathan Le Roux
The Synthesized Lakh (Slakh) Dataset contains 2100 automatically mixed tracks and accompanying MIDI files synthesized using a professional-grade sampling engine.
-

Tunebot
Mark Cartwright, Arefin Huq, Jinyu Han, Zafar Rafii, Bryan Pardo
The Tunebot project is an online Query By Humming system. As of Sept 25, 2014 Tunebot has had 296,472 site visitors. Users sing a song to Tunebot and it returns a ranked list of song candidates available on Apple’s iTunes website. The database that Tunebot compares to sung queries is crowdsourced from users as well. Users contribute new songs to Tunebot by singing them on the Tunebot website. The more songs people contribute, the better Tunebot works. Tunebot is no longer online but the dataset lives on.
-
VimSketch
Bongjun Kim, Mark Cartwright, Fatemeh Pishdadian, Bryan Pardo
VimSketch Dataset combines two publicly available datasets, created by the Interactive Audio Lab for the task of Query by Vocal Imitation (QBV).