Simultaneous Separation and Transcription of Mixtures with Multiple Polyphonic and Percussive Instruments¶
Abstract¶
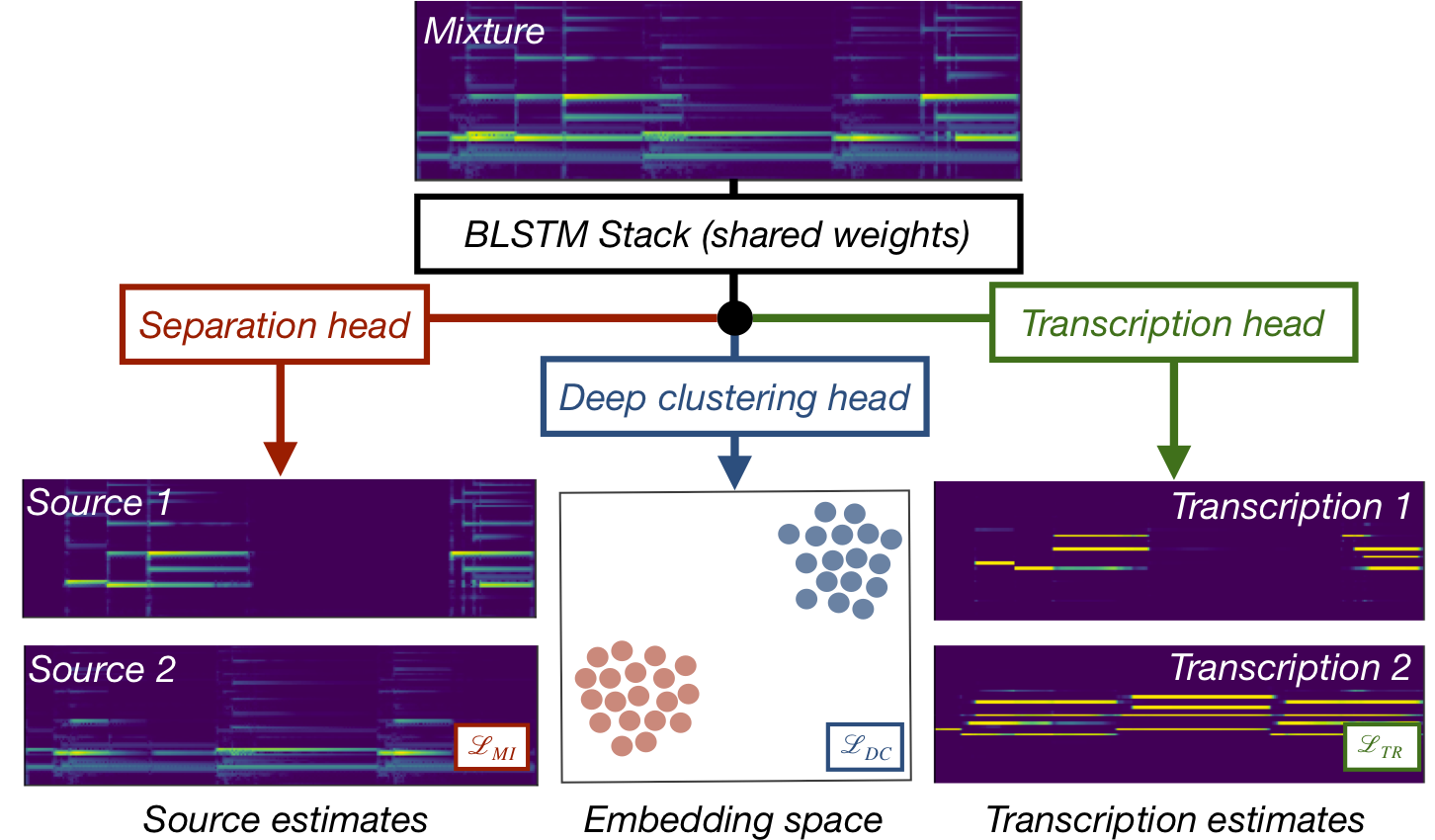
We present a single deep learning architecture that can both separate an audio recording of a musical mixture into constituent single-instrument recordings and transcribe these instruments into a human-readable format at the same time, learning a shared musical representation for both tasks. This novel architecture, which we call Cerberus, builds on the Chimera network for source separation by adding a third "head" for transcription. By training each head with different losses, we are able to jointly learn how to separate and transcribe up to 5 instruments in our experiments with a single network. We show that the two tasks are highly complementary with one another and when learned jointly, lead to Cerberus networks that are better at both separation and transcription and generalize better to unseen mixtures.
Presented at ICASSP 2020¶
Watch ICASSP Video¶
Read the paper here or here.¶
(This page best viewed on Firefox or Safari)
Architecture Overview¶
Example 1: Guitar/Piano Cerberus on YouTube Guitar & Piano Duet¶
from IPython.display import IFrame
IFrame(src="https://www.youtube.com/embed/87cnbLi0xBw?rel=0&showinfo=0;start=135&end=165", width="560", height="315")
Cerberus Piano/Guitar Model tested on above video from 2:15-2:45. (Audio downsampled to 16k below)
| Mixture | Separation Output | Transcription Output (re-synthesized) |
|||
|---|---|---|---|---|---|
| Guitar | Piano | Guitar | Piano | Remixed | |
Example 2: Guitar/Piano Cerberus on Jazz Piano & Guitar Duet¶
IFrame(src="https://www.youtube.com/embed/NfkpObyxIGQ?rel=0&showinfo=0;start=33&end=60", width="560", height="315")
Fred Herch (piano) & Bill Frisell (guitar) playing the song "Wave" from their album Songs We Know. (Audio downsampled to 16k below)
| Mixture | Separation Output | Transcription Output (re-synthesized) |
|||
|---|---|---|---|---|---|
| Guitar | Piano | Guitar | Piano | Remixed | |
Example 3: Guitar/Piano Cerberus on YouTube Violin & Piano Duet¶
IFrame(src="https://www.youtube.com/embed/RBx-Ue28KUE?rel=0&showinfo=0;start=45&end=60", width="560", height="315")
Here is an example of a Cerberus model trained on Guitar and Piano transcribing a duet with Violin and Piano! Cerberus Piano/Guitar Model tested on above video from 0:45-1:00. (Audio downsampled to 16k below)
| Mixture | Separation Output | Transcription Output (re-synthesized) |
|||
|---|---|---|---|---|---|
| Violin | Piano | Violin | Piano | Remixed | |
Example 4: Guitar/Piano/Bass/Drums Cerberus on a four piece band¶
IFrame(src="https://www.youtube.com/embed/B-bvtV29Pws?rel=0&showinfo=0;start=133&end=60", width="560", height="315")
From a karaoke version of The Beatles' "Oh! Darling". (Audio downsampled to 16k below)
| Mixture | Separation Output | Transcription Output (re-synthesized) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Guitar | Piano | Bass | Drums | Guitar | Piano | Bass | Drums | Remixed | |
Piano, Guitar, Bass¶
| Mixture | Separation Output | Transcription Output (re-synthesized) |
|||||
|---|---|---|---|---|---|---|---|
| Piano | Guitar | Bass | Piano | Guitar | Bass | Remixed | |
Piano, Guitar, Bass, Drums¶
| Mixture | Separation Output | Transcription Output (re-synthesized) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Piano | Guitar | Bass | Drums | Piano | Guitar | Bass | Drums | Remixed | |
Piano, Guitar, Bass, Drums, Strings¶
| Mixture | Separation Output | Transcription Output (re-synthesized) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Piano | Guitar | Bass | Drums | Strings | Piano | Guitar | Bass | Drums | Strings | Remixed | |
(Formatting for web below)
%%html
<style>
audio { width: 50px; }
</style>