The Northwestern University Source Separation Library (nussl) — Demo¶
nussl is an open source python library for audio source separation.¶
It is built to be easy to use existing source separation algorithms and to develop new algorithms. In this demo we will explore some basic functionality of nussl, including running and evaluating some source separation algorithms.
Let's get started by exploring how to import audio.
AudioSignal¶
The AudioSignal object is the entryway to using nussl. It provides an easy way to import an audio file into nussl. If you have ffmpeg installed, you can open many types of files in nussl.
import nussl # this is kind of important to do first...
path_to_source1 = "demo_files/drums.wav"
source1 = nussl.AudioSignal(path_to_source1)
source1.label = "mixture" # We can label this signal as a mixture or whatever else we want
utilities.audio(source1.audio_data.T, source1.sample_rate)
That's it! Now the audio is loaded into nussl and stored in an AudioSignal object. We can explore other aspects of this file with the AudioSignal object as well...
print("Path to file: {}" .format(source1.path_to_input_file))
print("Filename: {}" .format(source1.file_name))
print("Label: {}" .format(source1.label))
print("Sample Rate: {} Hz" .format(source1.sample_rate))
print("Length of file in samples: {}" .format(source1.signal_length))
print("Length of file in seconds: {}" .format(source1.signal_duration))
print("Number of channels: {}\n" .format(source1.num_channels))
print("Audio is stored at source1.audio_data:\n {}\n".format(source1.audio_data))
print("source1.audio_data is a numpy array: type(source1.audio_data)={}".format(type(source1.audio_data)))
print("source1.audio_data.shape = {}".format(source1.audio_data.shape))
print("\t\t\t(# channels, # samples)")
STFT¶
But, source1 has no stft data yet. Because we haven't actually computed the STFT.
We can calculate an STFT very easily from our AudioSignal object. Let's do that:
# This returns stft data...
stft = source1.stft(window_length=1024, hop_length=512)
# ...but it's still stored in the AudioSignal object
print(source1.stft_data.shape)
print('(# FFT bins, # time bins, # channels)')
mag = source1.magnitude_spectrogram_data # np.abs(source1.stft_data)
psd = source1.power_spectrogram_data # np.pow(source1.stft_data, 2)
Source separation¶
It's simple to run source separation algorithms on audio. The first argument to source separation classes is always an AudioSignal object. The process to use a source separation algorithm is the following:
- Initialize a source separation object.
- Run the source separation object using
obj.run(). - The output is stored as
AudioSignalobjects. Callobj.make_audio_signals()to get the output. - Write audio to disc or listen to it. (Optional)
Let's demonstrate.
mixture_path = 'demo_files/HistoryRepeating_PropellorHeads.wav'
# Step 0 - load a new mixture
mixture = nussl.AudioSignal(mixture_path)
print('Mixture')
utilities.audio(mixture.audio_data.T, mixture.sample_rate)
# Step 1 - initialize a Repet object
repet_sim = nussl.RepetSim(mixture)
# Step 2 - run the algorithm
repet_sim.run()
# Step 3 - get the output
bg, fg = repet_sim.make_audio_signals()
# Step 4 - hear the output
print('Estimated Foreground')
utilities.audio(fg.audio_data.T, fg.sample_rate)
print('Estimated Background')
utilities.audio(bg.audio_data.T, bg.sample_rate)
Importantly, this is an API! Every algorithm in nussl is written to this API, so any algorithm works like this!
We can run a bunch of algorithms in a loop, like so:
# Run three disparate algorithms
separation_algorithms = [nussl.HPSS, nussl.RepetSim, nussl.RPCA]
mixture = nussl.AudioSignal(mixture_path)
for alg in separation_algorithms:
# Steps 1-3 as above
instance = alg(mixture)
instance.run()
bg, fg = instance.make_audio_signals()
# Hear results
print('{} foreground estimation:'.format(str(instance)))
utilities.audio(fg.audio_data.T, fg.sample_rate)
print('{} background estimation:'.format(str(instance)))
utilities.audio(bg.audio_data.T, bg.sample_rate)
print('\n')
Here's a list of all of the algorithm's in nussl that are currently built to the API spec:
print('\n'.join([a.__name__ for a in nussl.all_separation_algorithms]))
Dataset Integration¶
While nussl does not ship with any data sets, it does integrate with many common source separation data sets, such as MIR-1K, iKala, and MUSDB18 (the new combination of SiSEC's DSD100 and MedleyDB).
The dataset integrations take the form of python generator functions. They spit out a new set of AudioSignal objects every loop. Only one set of files is in memory at a time. The syntax for all of the supported datasets is the same.
Here's an example with MIR-1K:
mir1k_path = '/Users/ethanmanilow/Documents/Github/SourceSeparationPyCharm/demo_files/MIR-1K'
# THIS is the generator
# there are lots of options, some are standardized
# But some are specific to the dataset
mir1k = nussl.datasets.mir1k(mir1k_path,
check_hash=True, # <-- part of API standard, this can be skipped to save time
shuffle=False, # <-- also part of API standard
undivided=False) # <-- specific to MIR-1k (undivided -> use the undivided MIR-1K files)
i = 1
max_ = 5
for mixture, vocals, accompaniment in mir1k:
print('Label: {},\t\t\t Name: {}'.format(mixture.label, mixture.file_name))
print('\tLabel: {},\t\t Name: {}'.format(vocals.label, vocals.file_name))
print('\tLabel: {},\t Name: {}\n'.format(accompaniment.label, accompaniment.file_name))
# Stop early for bevity's sake
if i >= max_:
break
i += 1
Evaluation¶
In addition to running source separation algorithms, researchers can also evaluate algorithms in the library. There is support for common evaluation measures. Though the most frequently used are the BSS-Eval metrics, nussl also has support for calculating the precision, recall, f-score, and accuracy of binary masks. All evaluation classes are build to an API, and thus extensible if more evaluation measures are needed in the future.
Here's a simple example of using BSS-Eval (a more complex version is below):
# Let's just load the next example from MIR-1K
mixture, vocals, accompaniment = next(mir1k)
mixture.to_mono(overwrite=True) # "Mix" the left and right channels together
# Run Repet
r = nussl.Repet(mixture)
r.run()
bg_est, fg_est = r.make_audio_signals()
# Run evaluation using the new BSS-Eval v4 from museval
bss = nussl.evaluation.BSSEvalV4(mixture, [vocals, accompaniment], [fg_est, bg_est])
bss_scores = bss.evaluate()
print(json.dumps(bss_scores, indent=2, sort_keys=True))
Deep Learning Models and the External File Zoo (EFZ)¶
While nussl does not ship with any pre-trained models, it has the ability to download pre-trained models stored on the nussl servers. The nussl servers are called the External File Zoo (EFZ) and a companion website is located here.
To see what models are currently available on the nussl EFZ, use this utility function:
nussl.efz_utils.print_available_trained_models()
There's only one up there at the time of this writing. More are coming soon...
Once we know the file name of the model we want, we can download it like so:
nussl.efz_utils.download_trained_model('deep_clustering_vocals_44k_long.model')
Contributing to nussl¶
In addition to trained deep learning models, the EFZ also houses example audio files and benchmark files for unit testing in nussl. As such, it is a crucial part of contributing to nussl. The developers of nussl are committed to accepting contributions, so we encourage researchers to submit their algorithms (with or without models). For more details please see the contributions section on the nussl github page.
Example Uses of nussl¶
Here we showcase a lot of the features of nussl by exploring some novel use cases.
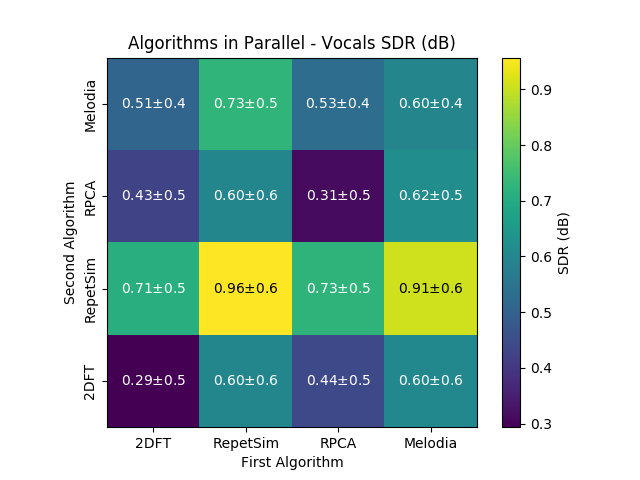
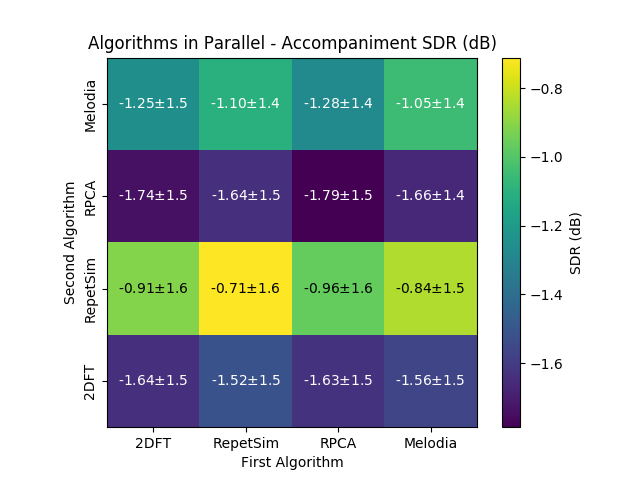
Cascading Algorithms¶
This is the actual code that was run to generate the results shown in the ISMIR 2018 paper. Click the arrows to expand the functions and see the code.
def weiner_filter_masks(mask1, mask2):
"""
Simple weiner filtering method, helper function for cascading code (below)
"""
den = mask1 + mask2
return nussl.separation.SoftMask(mask1 / den), nussl.separation.SoftMask(mask2 / den)
def parallel(signal, alg1, alg2, bg_weight, fg_weight,
alg1_kwargs=None, alg2_kwargs=None, mask_type='soft'):
"""
Running alg1 and alg2 in parallel, weighing their output masks, and combining
masks with a simple weiner filter.
"""
# Any optional parameters?
alg1_kwargs = alg1_kwargs if alg1_kwargs is not None else {}
alg2_kwargs = alg2_kwargs if alg2_kwargs is not None else {}
# Set up both algorithms
inst1 = alg1(signal, mask_type=mask_type, **alg1_kwargs)
inst2 = alg2(signal, mask_type=mask_type, **alg2_kwargs)
# Run algorithms
bk_mask1, fg_mask1 = inst1.run()
bk_mask2, fg_mask2 = inst2.run()
# Combine the masks using weight parameters
bk_mask = bk_mask1.mask * bg_weight + ((1 - bg_weight) * bk_mask2.mask)
fg_mask = fg_mask1.mask * fg_weight + ((1 - fg_weight) * fg_mask2.mask)
# Weiner filter the masks
background_mask, foreground_mask = weiner_filter_masks(bk_mask, fg_mask)
# Apply masks to signal and compute iSTFT
bg = signal.apply_mask(background_mask, overwrite=False)
bg.istft(truncate_to_length=signal.signal_length)
fg = signal.apply_mask(foreground_mask, overwrite=False)
fg.istft(truncate_to_length=signal.signal_length)
# Done
return bg, fg
def series(signal, alg1, alg2, weight,
alg1_kwargs=None, alg2_kwargs=None, mask_type='soft'):
"""
Running alg1 and alg2 in series, weighing their output masks, and combining
masks with a simple weiner filter.
Returns:
"""
# Any optional parameters?
alg1_kwargs = alg1_kwargs if alg1_kwargs is not None else {}
alg2_kwargs = alg2_kwargs if alg2_kwargs is not None else {}
# Set up and run algorithm 1
inst1 = alg1(signal, mask_type=mask_type, **alg1_kwargs)
bk_mask1, fg_mask1 = inst1.run()
bg_est1, fg_est1 = inst1.make_audio_signals()
# Set up and run algorithm 2, with the output of algorithm 1 (fg_est)
inst2 = alg2(fg_est1, mask_type=mask_type, **alg2_kwargs)
bk_mask2, fg_mask2 = inst2.run()
fg_mask2 = lib.separation.SoftMask(np.minimum(fg_mask2.mask, fg_mask1.mask))
# Combine masks using the weight parameter
bk_mask = bk_mask1.mask + weight * bk_mask2.mask
fg_mask = fg_mask2.mask + (1 - weight) * bk_mask2.mask
# Weiner filter the masks
background_mask, foreground_mask = weiner_filter_masks(bk_mask, fg_mask)
# Apply masks to signal and compute iSTFT
bg = signal.apply_mask(background_mask, overwrite=False)
bg.istft(truncate_to_length=signal.signal_length)
fg = signal.apply_mask(foreground_mask, overwrite=False)
fg.istft(truncate_to_length=signal.signal_length)
# Done
return bg, fg
def run_cascading():
"""
Runs the
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
WARNING: This will take a LOOOOONG time to run!!!!
It took between ~36-48 hours on my machine!!!!!!
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
"""
mir1k_dir = 'demo_files/MIR-1K'
output_dir = 'cascade_results'
separation_classes = [nussl.RepetSim, nussl.FT2D, nussl.RPCA, nussl.Melodia]
separation_combinations = [a for a in itertools.product(separation_classes, separation_classes)]
p_bg_w = 1.0 # parallel background mask weight
p_fg_w = 0.3 # parallel foreground mask weight
series_w = 0.4 # series mask weight
start = time.time()
checkpoint_scores = {}
i = 1
for mixture, vocal, accompaniment in nussl.datasets.mir1k(mir1k_dir, undivided=True):
print('~*' * 50)
print('Working on {}. {}/110'.format(mixture.file_name, i))
print('~*' * 50)
mixture.to_mono(overwrite=True)
mixture.stft()
i += 1
for alg1, alg2 in separation_combinations:
n1, n2 = alg1.__name__, alg2.__name__
if n1 not in checkpoint_scores:
checkpoint_scores[n1] = {}
if n2 not in checkpoint_scores[n1]:
checkpoint_scores[n1][n2] = {}
combined_name = '{} {}'.format(n1, n2)
print('\nStarting {}'.format(combined_name))
# ############### PARALLEL ################
print('\tRunning Parallel')
try:
fg_est, bg_est = parallel(mixture, alg1, alg2, p_bg_w, p_fg_w)
print('\t\tComputing BSS-Eval')
bss = nussl.evaluation.BSSEvalV4(mixture, [vocal, accompaniment], [fg_est, bg_est])
bss_scores = bss.evaluate()
if 'parallel' not in checkpoint_scores[n1][n2]:
checkpoint_scores[n1][n2]['parallel'] = []
checkpoint_scores[n1][n2]['parallel'].append(bss_scores)
except Exception:
print('Error running Parallel on {}'.format(mixture.file_name))
# ############### SERIES ################
print('\tRunning Series')
try:
fg_est, bg_est = series(mixture, alg1, alg2, series_w)
print('\t\tComputing BSS-Eval')
bss = nussl.evaluation.BSSEvalV4(mixture, [vocal, accompaniment], [fg_est, bg_est])
bss_scores = bss.evaluate()
if 'series' not in checkpoint_scores[n1][n2]:
checkpoint_scores[n1][n2]['series'] = []
checkpoint_scores[n1][n2]['series'].append(bss_scores)
except Exception:
print('Error running Series on {}'.format(mixture.file_name))
with open(os.path.join(output_dir, 'cascade_results.json'), 'w') as f:
json.dump(jsonpickle.encode(checkpoint_scores), f, indent=2)
elapsed = time.time() - start
print('Saved checkpoint. Time elapsed = {}'.format(str(timedelta(seconds=elapsed))))
And here are the results (as presented in ISMIR 2018) from the cascading experiments running on the undivided MIR-1K dataset.
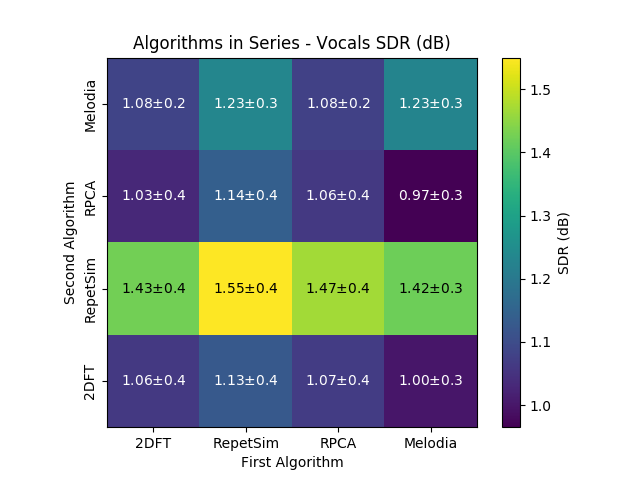
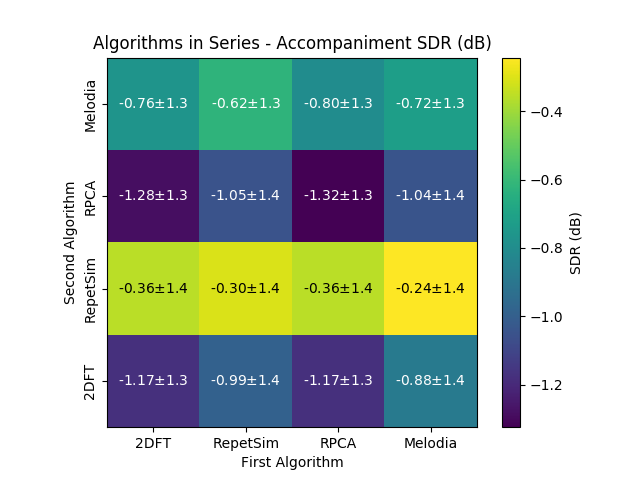
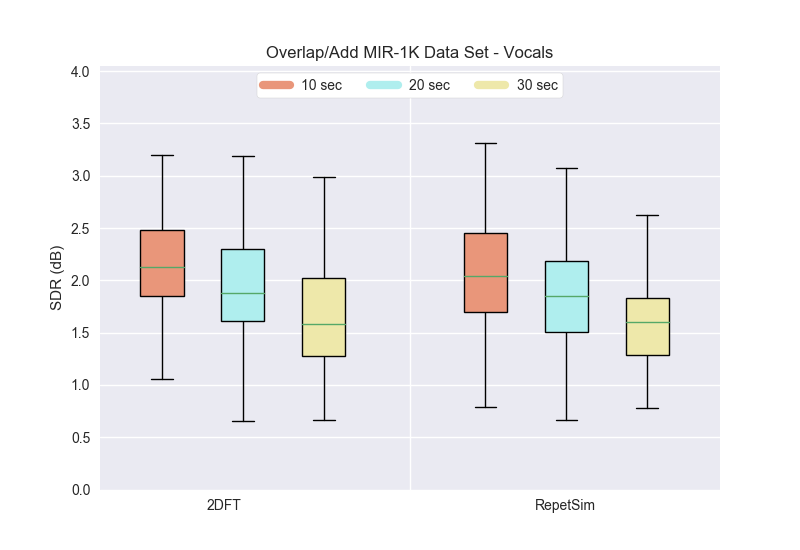
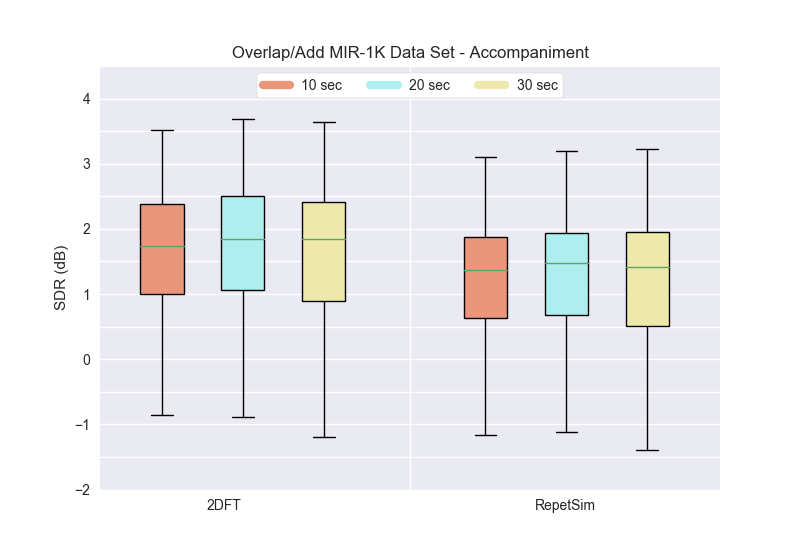
Overlap and Adding¶
The code for this is much simpler, as OverlapAdd already exists as a class in nussl.
For this experiment, we tested three different window sizes--10, 20, 30 seconds--using two different algorithms--RepetSim, and 2DFT (called FT2D in the library). Click the arrows to expand the functions and see the code.
def run_overlap_add():
separation_classes = [nussl.RepetSim, nussl.FT2D]
mir1k_dir = 'demo_files/MIR-1K'
output_dir = 'demo_files/output'
window_sizes = [10, 20, 30] # Test three window sizes: 10sec, 20sec, and 30sec
start = time.time()
checkpoint_scores = {}
i = 1
for mixture, vocal, accompaniment in nussl.datasets.mir1k(mir1k_dir, undivided=True):
print('~*' * 50)
print('Working on {}. {}/110'.format(mixture.file_name, i))
print('~*' * 50)
mixture.to_mono(overwrite=True)
checkpoint_scores[mixture.file_name] = {}
i += 1
m_name = mixture.file_name
for alg in separation_classes:
a_name = alg.__name__
if a_name not in checkpoint_scores[m_name]:
checkpoint_scores[m_name][a_name] = {}
for win in window_sizes:
ola = nussl.OverlapAdd(mixture, alg, overlap_window_size=win,
overlap_hop_size=win//2,
overlap_window_type=nussl.WINDOW_DEFAULT)
ola.run()
bg, fg = ola.make_audio_signals()
bss = nussl.evaluation.BSSEvalV4(mixture, [vocal, accompaniment], [fg, bg])
bss_scores = bss.evaluate()
if win not in checkpoint_scores[m_name][a_name]:
checkpoint_scores[m_name][a_name][win] = {}
means = bss_scores['sdr_means']
checkpoint_scores[m_name][a_name][win] = means
with open(os.path.join(output_dir, 'mir1k_overlap_add.json'), 'w') as f:
json.dump(jsonpickle.encode(checkpoint_scores), f, indent=2)
elapsed = time.time() - start
print('Saved checkpoint. Time elapsed = {}'.format(str(timedelta(seconds=elapsed))))
Here are the results from the overlap/add experiment (as presented in ISMIR2018). This experiment was run on the MIR-1K dataset.